|
Arrow Lake 概述 直接进主题吧。 Arrow Lake 身上有几个第一。 首先,它是 Intel 第一次找台积电生产的高性能桌面处理器。在这之前,Intel 其实也有找过其他厂商代工芯片,但是在高性能桌面处理器方面这次头一遭。 Intel 在很长一段时间里都对半导体工艺倾注大量的资源,使得其生产工艺一直领先于同行,即使 IBM 也有宣布过更先进的制程,但是 Intel 一直以更高成熟度和规模化量产能力自豪。但是在前几年,Intel 的上层认为既然遥遥领先了,那就干脆搞起加大架构优化力度,减少提升生产技术的投入。 我也曾经和许多人一样,认为龟兔赛跑的结果在现实中很难出现,然而这样的事情可能比我们想象的要更普遍,Intel 的 Bunny 装广告很多人都看到过,我们是真的将其视作兔子,其竞争对手只是乌龟。然而事情就这样发生了,经历多年的躺平后,Intel 终于走到了这一步。 其次,这是自从 2002 年 Pentium 4 从 Project Jackson 引入超线程技术后 Intel 第一次在桌面处理器上取消对超线程技术支持。 这事情其实挺好理解的,超线程一直是有争议的,它的初衷让 CPU 闲置的流水线单元得到充分使用,最高可以提升 20% 到 30% 的多线程性能,但是会有部分物理架构资源因此被平分,是一柄双刃剑。 Intel 表示,去掉多线程支持后,芯片的单元格复杂性大大降低。此外,现在 Arrow Lake 的 E-CORE 今非昔比,性能极强,在目前动辄 20 多个内核的情况下,强大的 E-Core 是让 Intel 决定去掉超线程支持的一个重要前提。 还有就是,Intel 首次在桌面处理器上启用 Foveros 3D 封装技术。 该技术之前在笔记本处理器领域率已经先启用了,在桌面上启用也是顺利成长的事情。虽然也可以视作 chiplet 的一种实现方式,但是和 AMD 不同的是,Foveros要紧密得多,能实现更低的时延和每 bit 传输能耗。 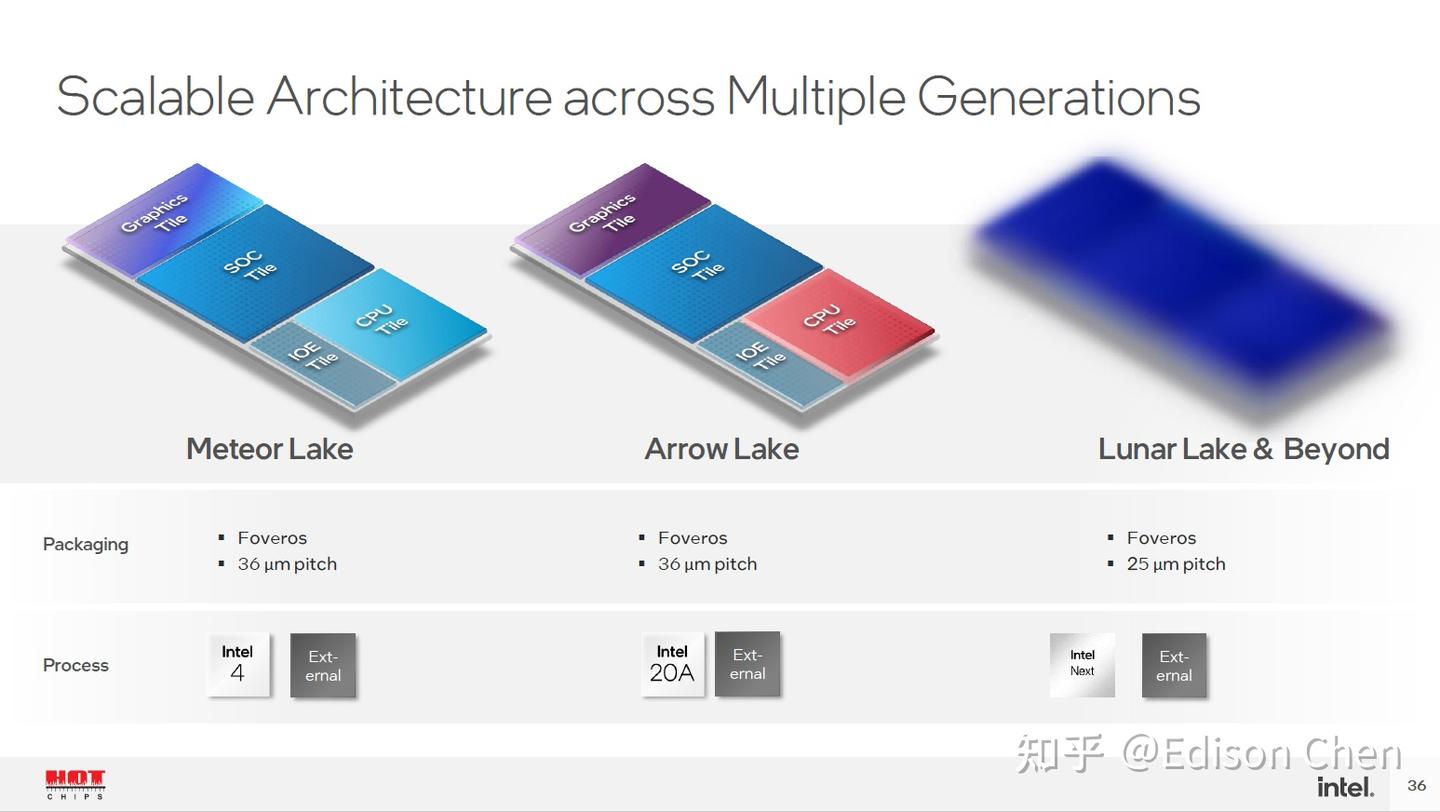
上图是去年 Hotchips 上的幻灯片,这时候的 Arrow Lake 还是打算使用 Intel 自己的 Intel 20A 制程,之后变成了 i5 以上台积电 N3B,最终决定则是全都使用台积电工艺生产。 从这个幻灯片看到的另一个信息是,Arrow Lake 的 Foveros 封装采用的第一代,其 bump pitch(引脚间距)尺寸为 36μ um,每 bit 的传输能耗 0.15 皮焦耳。按照 Intel 的路线图,下一代处理器 Luna Lake 将会采用名为 Foveros Omni 技术,引脚间距缩短到 25 μm,每 bit 能耗为小于 0.15 皮焦耳,未来的 Foveros Direct 的引脚间距则是进一步提升到小于 10 μm,每 bit 能耗降低到 0.05 皮焦耳以下。 产品规格和定价第一波 Arrow Lake 桌面产品有 5 款产品,分别是 245KF、245K、265KF、265K 以及 285K: 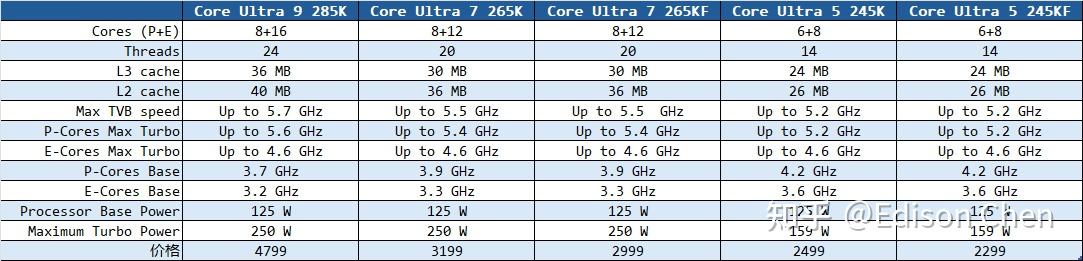
作为对比,目前 Intel 京东自营的 14700K 报价是 2798元,14600K 是 1849 元。 在官方的规格表里,虽然内存最高规格是 DDR5-6400 MT/s,但是实测表面,285K 可以轻松实现 DDR5-8000 MT/s,这个规格据闻被考虑作为 Arrow Lake 内存配置 sweat spot。 虽然使用了更先进的制程,但是 Arrow Lake 的耗电依然挺高的,最高功耗设定是 250W,如果解除功耗约束,在 y-cruncher(多线程 pi 计算软件)中实测(SFT 烤机子项目)功耗能达到 350 瓦级别。 800 系芯片组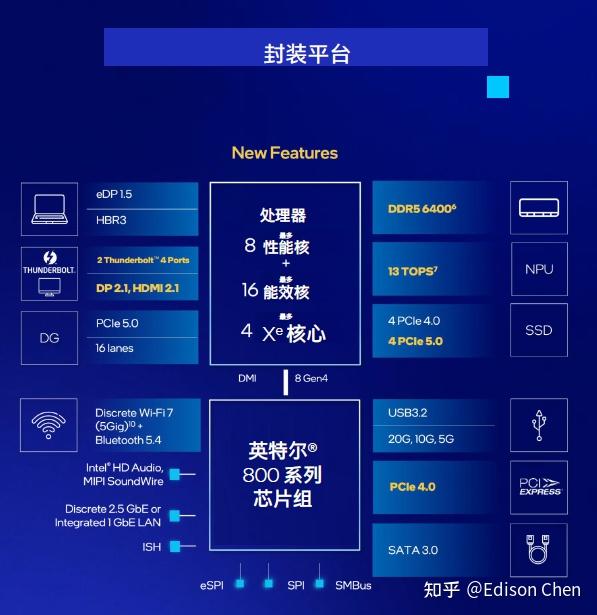
芯片组方面,这次搭配的最高端芯片组为 Z890,主要改进之处是提供了 24 条 PCIE 4.0 通道(比 Z790 增加了 4 条),其余部分没啥变化。 
上图是这次测试使用到的华硕 ROG Maximus Hero 主板,四内存槽设计,在两条内存的时候,能轻松达到 DDR5-8000 MT/s,但是如果是插满四槽内存只能跑到 6800MT/s。 伴随 Arrow Lake 一起推出市场的还有名为 CUDIMM 的新式内存条,它的引脚和目前的 UDIMM 兼容,但是内存条上集成了名为 CKD 的时钟驱动芯片,在牺牲一点时延的情况下能让内存频率跑得更高(目前的情况是 8000 起步,能跑到 10000 MT/s 级别,当然我觉得这其实还是比较有挑战性的)。 测试平台CPU: Intel Core Ultra 9 285K、Ultra 7 265K;Intel Core i9 14900K;AMD Ryzen 9 9950X 主板:华硕 ROG Maxiums HERO、ROG MAXIMUS Z790 APEX、MSI PRO X870-P WIFI 内存: Intel 平台 DDR5 8000 34-46-46-58,tREFI=32767 AMD 平台 DDR5 7600 34-46-46-58,tREFI=32767 底层测试的大部分基本都是手动设置为 4GHz 下测试,例如每周期内存带宽、内存时延、微架构测试等都是 4GHz,而访存功耗、总内存带宽都是默认频率下跑的。 内存/Cache 带宽、时延以及能耗比单线程每周期字节带宽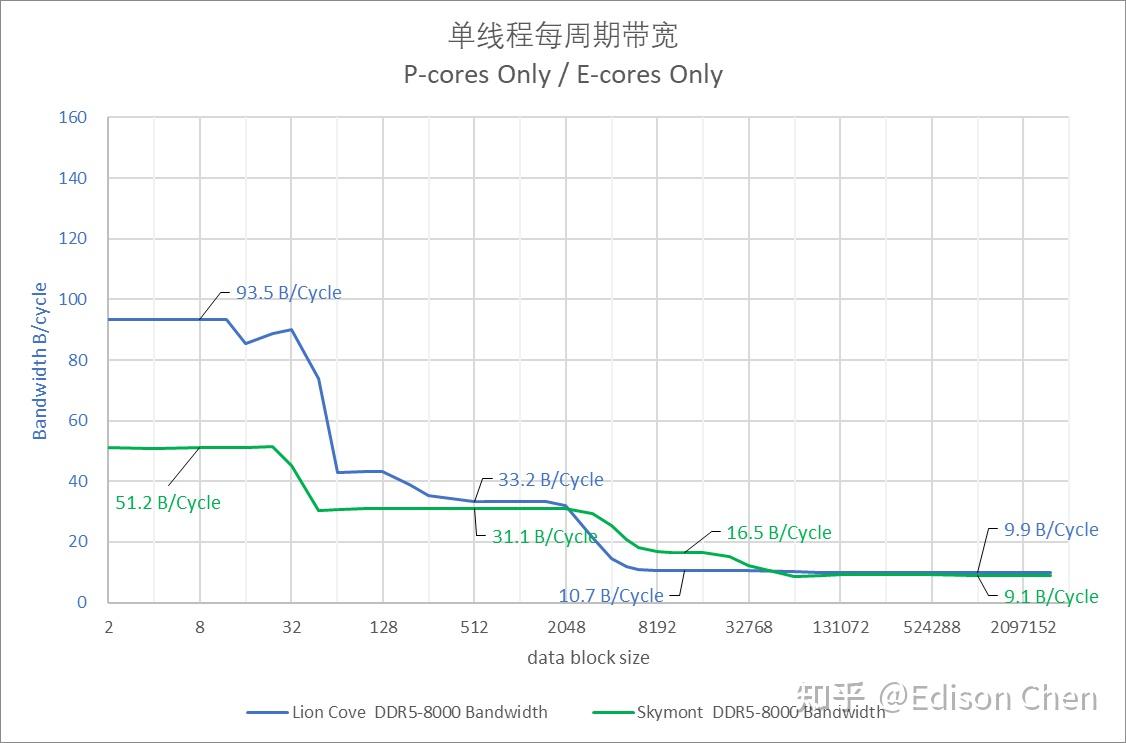
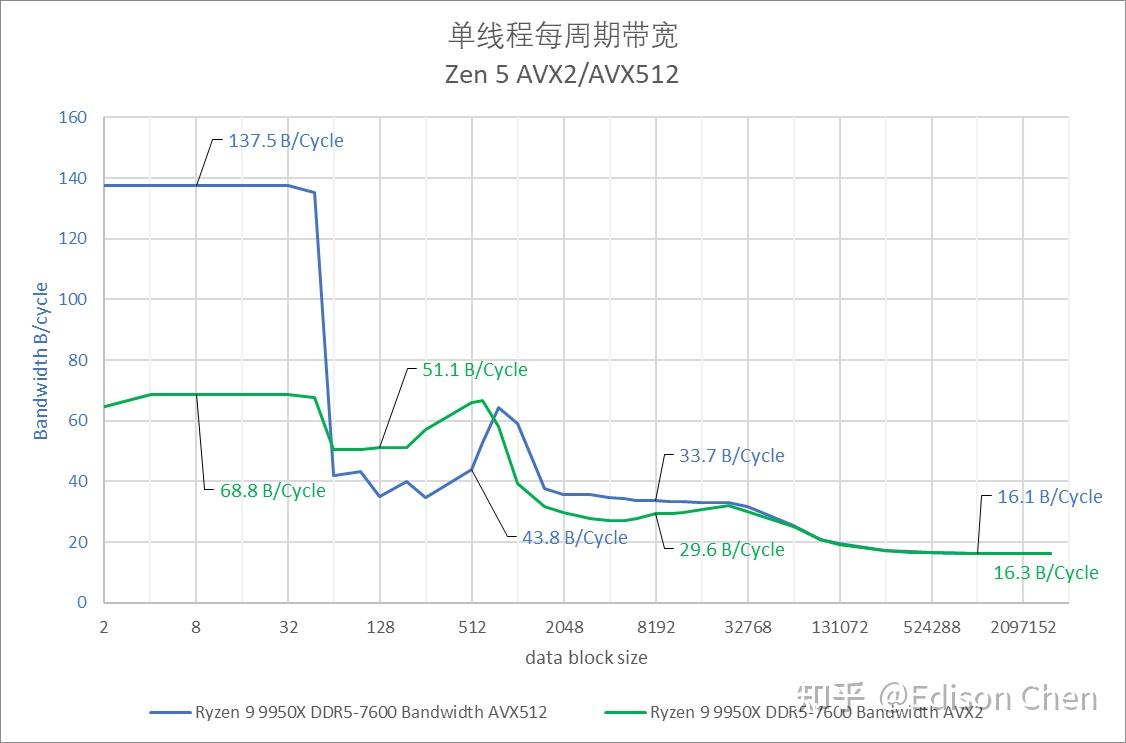
Lion Cove(Arrow Lake 的 P-Core)在 AVX2 指令下提供每周期 94 字节的 L1 Cache 带宽,而 Zen5 AVX2 此时是每周期 69 字节。 在进入 L3 Cache 阶段后,Zen5 AVX2 的每周期读取带宽是 29.6 字节,Lion Cove 此时则只有每周期 10.7 字节。 进入内存阶段后,Intel 只能实现每周期 10 字节的读取带宽,而 Zen5 AVX2/AVX512 此时是每周期 16 字节。 单线程带宽 @ 4GHz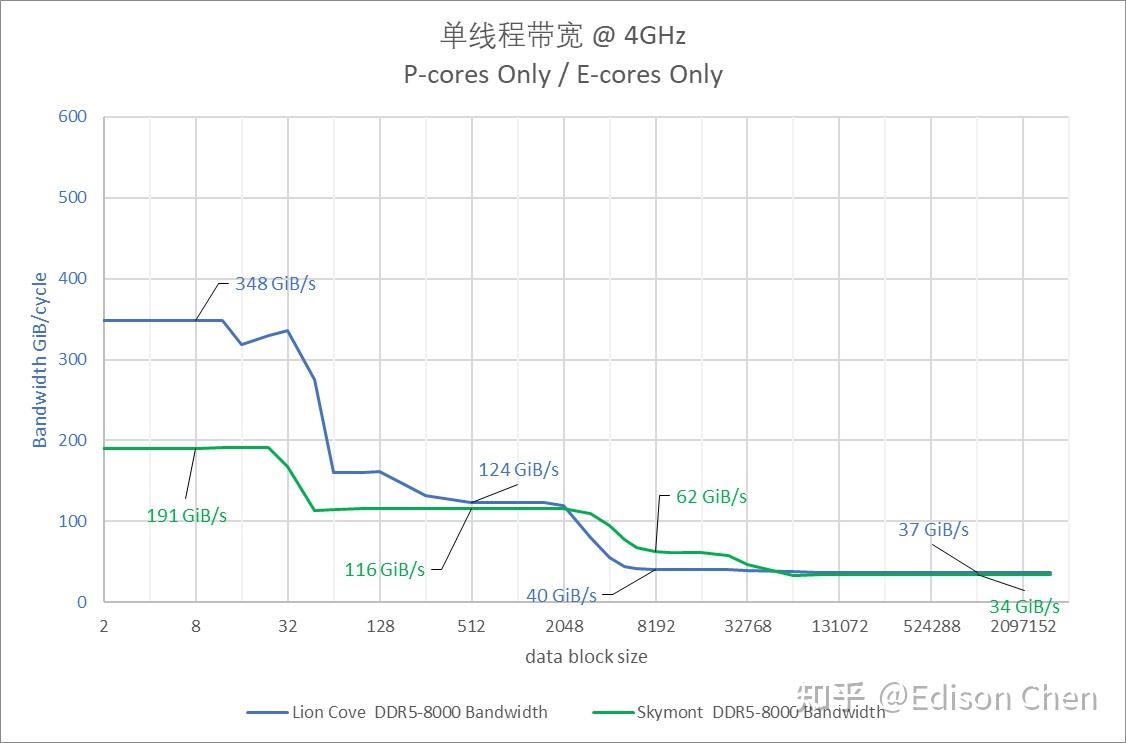
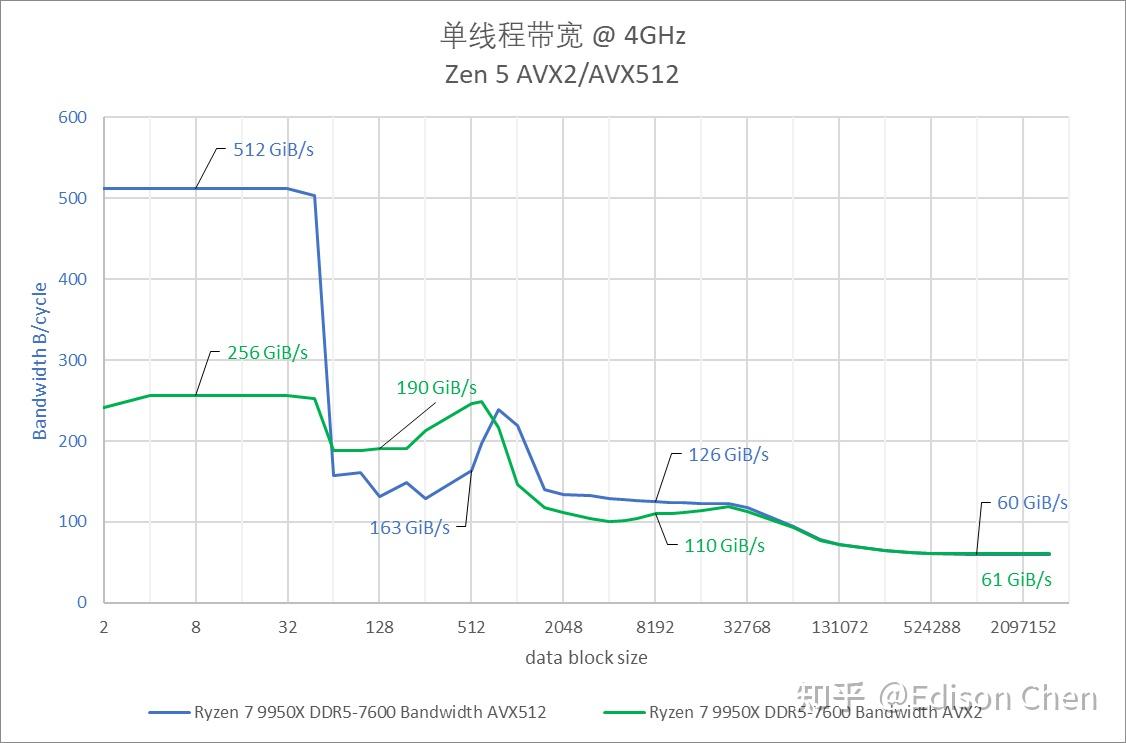
在 4GHz 下的绝对内存带宽方面,Lion Cove AVX2 在 L1 Cache 阶段能达到每秒 348 GiB,而 Zen5 时每秒 256 GiB。 Skymont 在 L3 Cache 阶段的内存带宽居然比 Lion Cove 高 50%。 默认频率单线程内存带宽/能耗比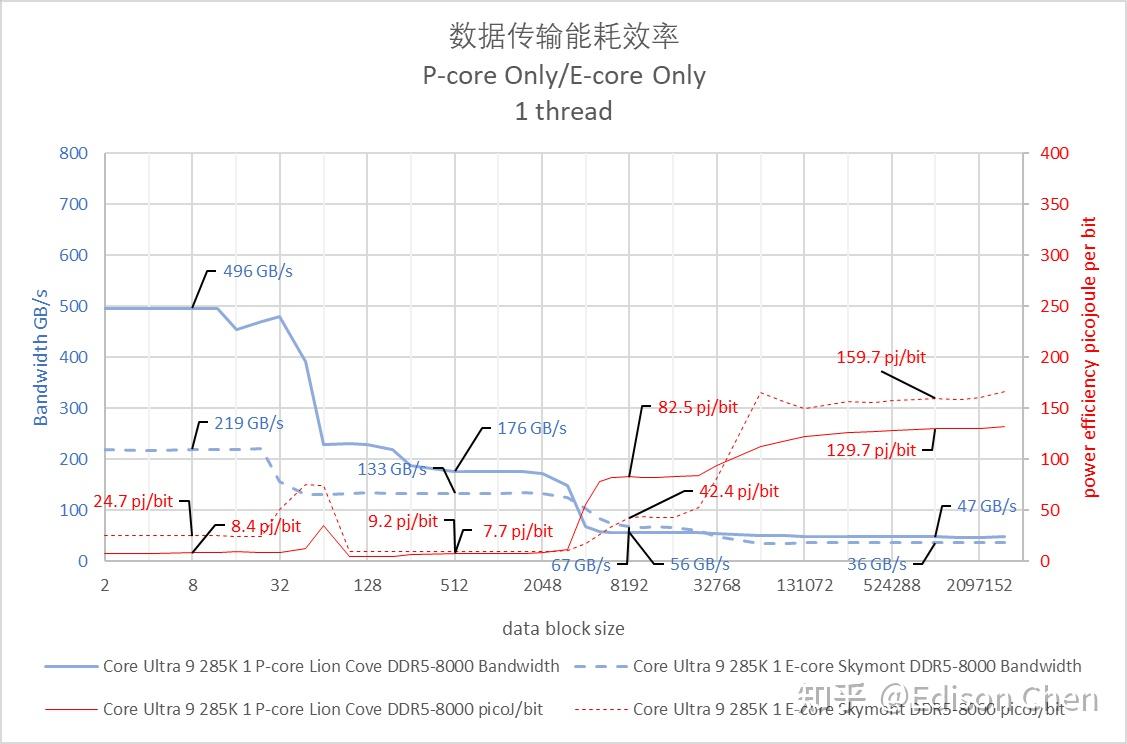
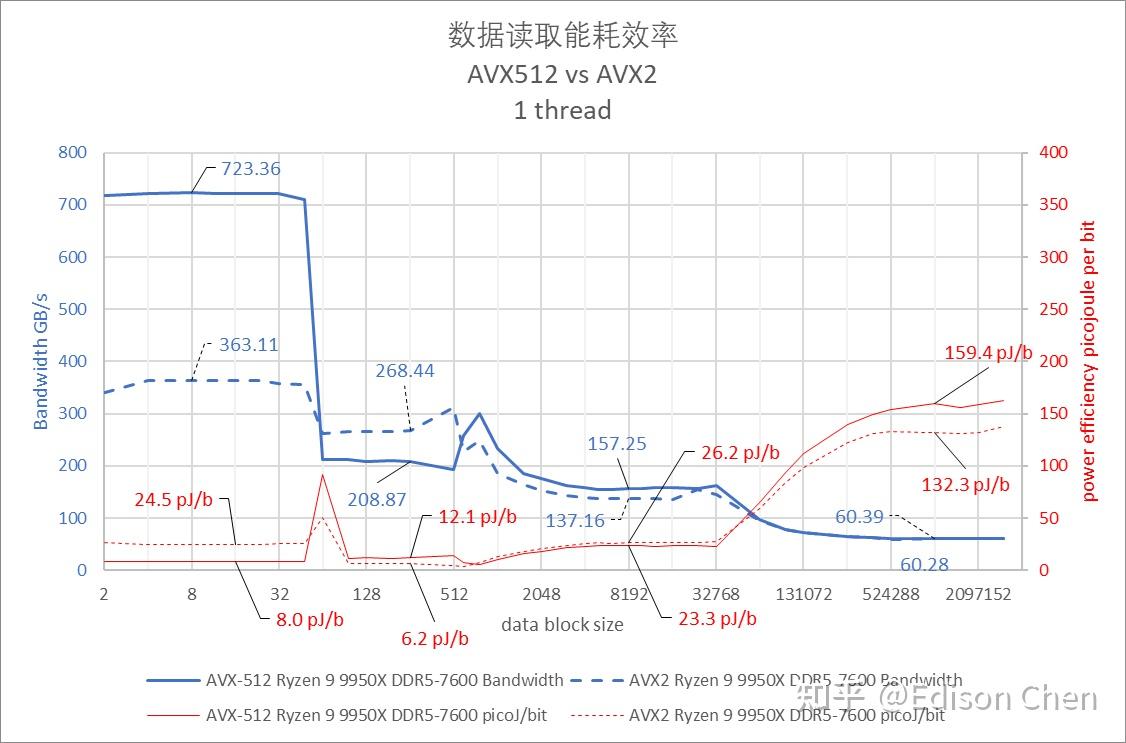
从单线程默频访存带宽能耗测试结果来看,在 L1 Cache 阶段,Lion Cove 可以做到每秒 496 GiB 带宽,Skymont 是每秒 219 GiB 或者说 Lion Cove 的 44%。 在访存能耗比方面,Zen5 在 Cache 阶段表现更出色,尤其是 L3 Cache 部分,每 bit能耗更是只有 Lion Cove 的 31.8%,这是有点让人感到意外的,毕竟理论上 Intel 的封装更紧凑。 默认频率多线程全核内存带宽/能耗比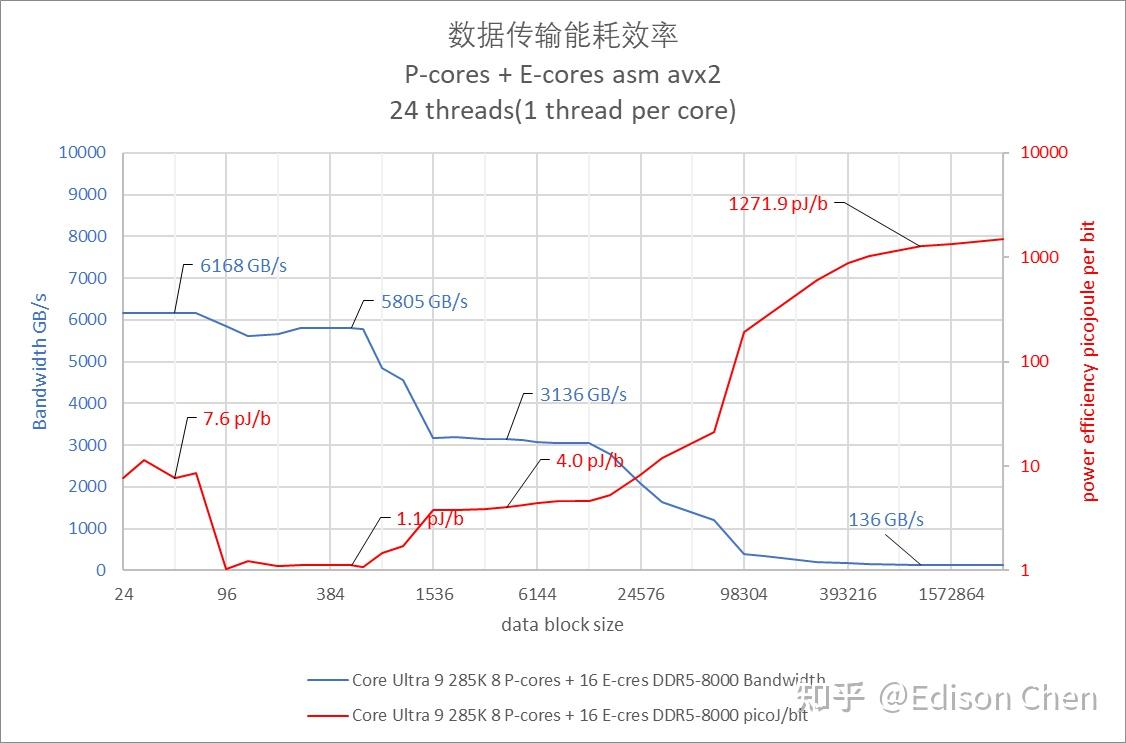
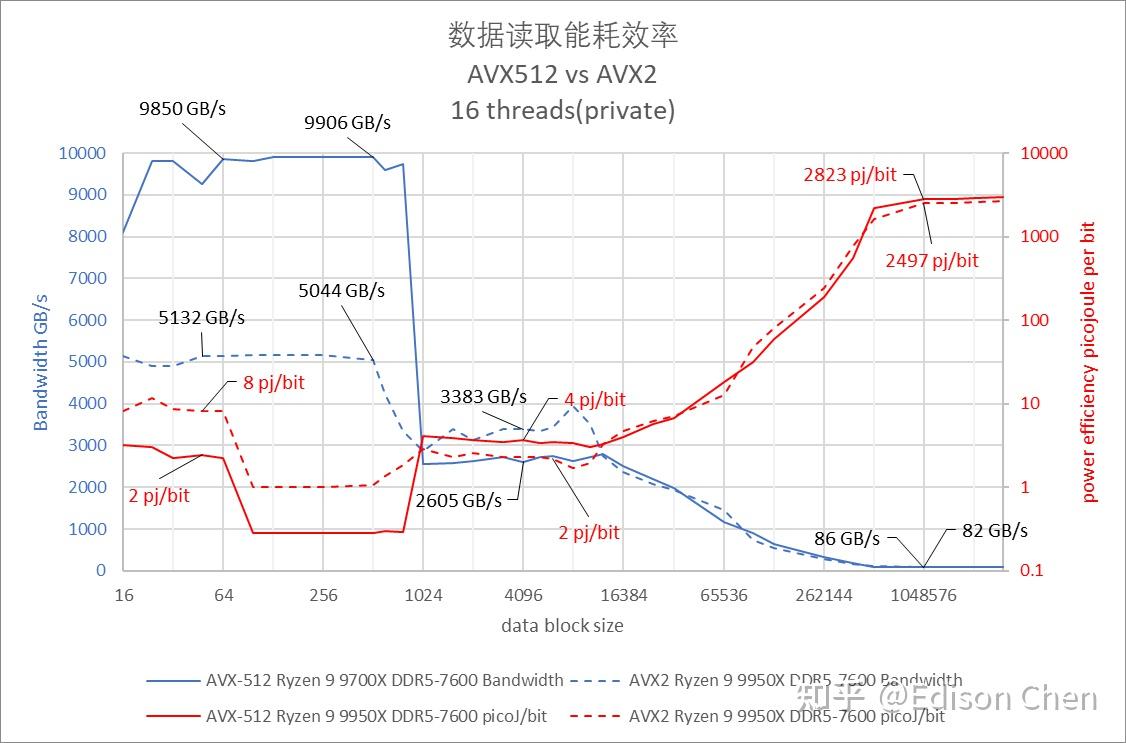
在全核情况下,285K 在内存阶段的每 bit 耗电要远低于 9950X,Intel 的 Foveros 封装在这里应该发挥了一定作用。 当然 9950X 本身的内存阶段带宽也是委实有点偏低,只有每秒 86 GiB,而在 285K 则是每秒 136 GiB/s 内存时延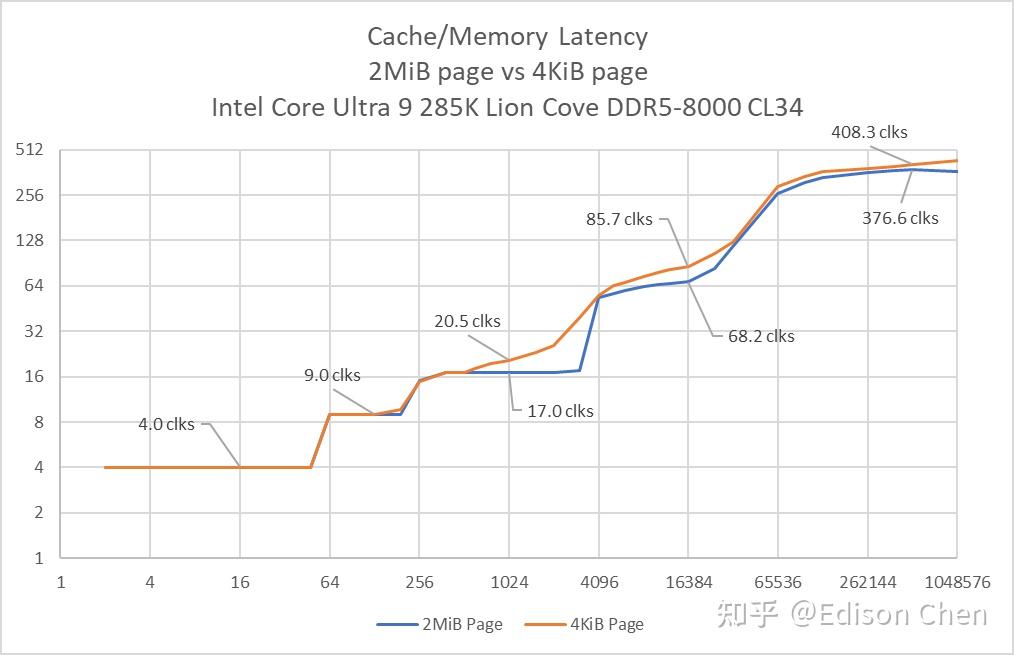
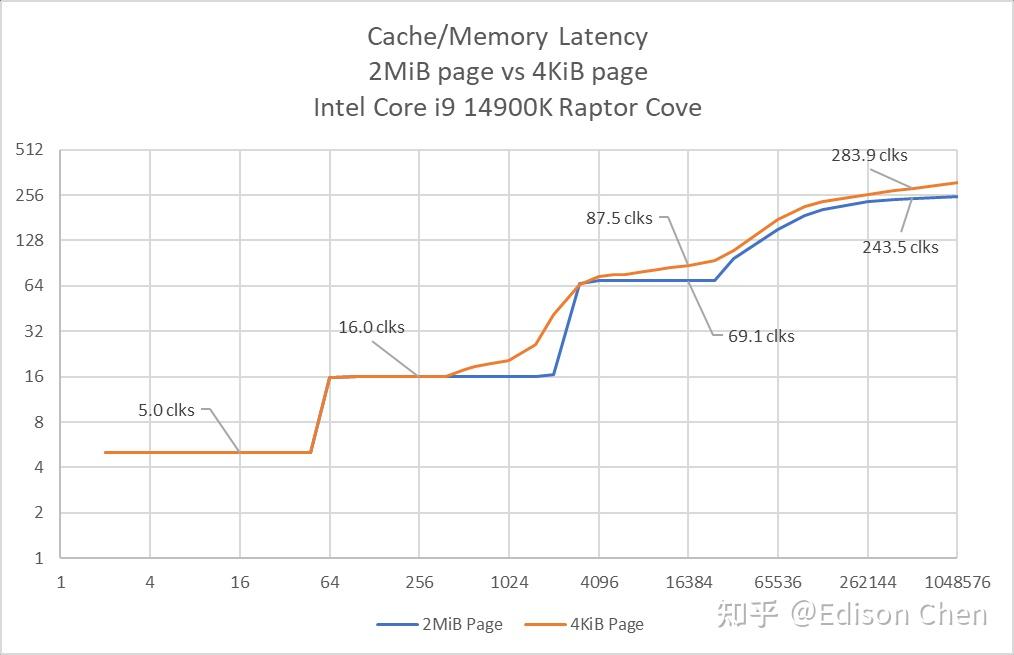
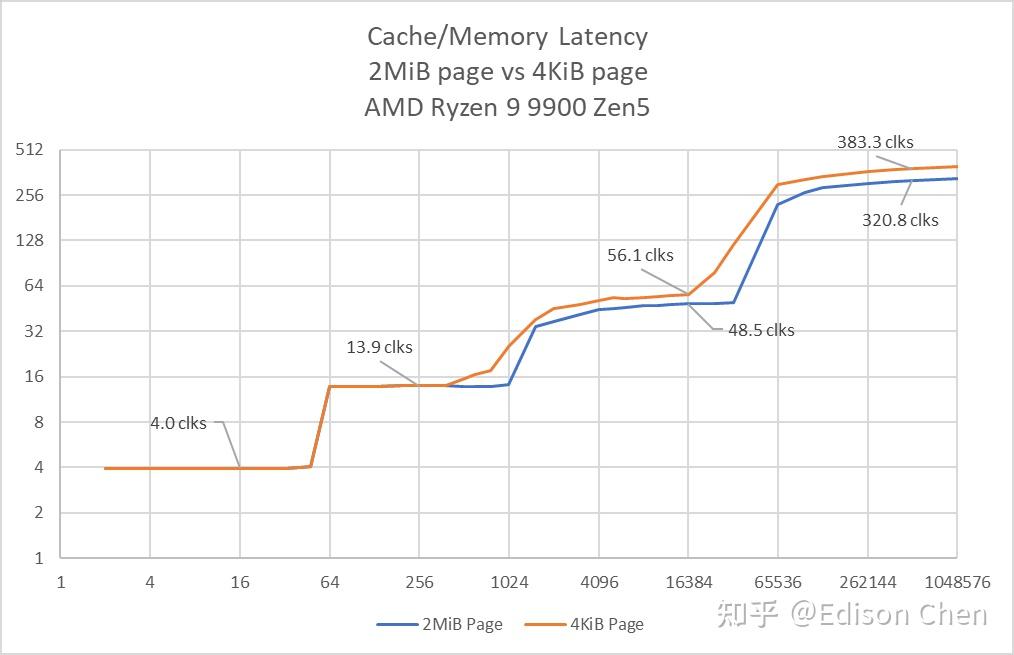
Linux 默认的分页是 4KiB,在时延测试中,很容易出现 TLB 命中缺失导致的 Cache 时延跃变不清晰的问题,因此我这里增加了 HugePage(2MiB)分页下的时延测试结果。 所谓分页大小,是指 CPU 和操作系统在执行物理、虚拟内存地址转换的时候用到的缓存每个条目对应的内存块大小,4KiB 就是指每个 TLB 条目能对应一个 4KiB 连续大小的内存块,2 MiB 对应的内存块要大许多,所以不太容易出现 TLB 命中缺失的情况,也因此 Cache 时延测试跃变会更明显。 Lion Cove 新引入了一个 L0 DCache,其大小为 48KiB,时延为 4 个周期,L1 DCache 时延是 9 个周期,大小为 192 KiB。 目前的大部分软件都只是把 L0 DCache 当作是传统 L1 DCache,从性能表现看,我觉得这个判断没啥问题,在 Lion Cove 里 Data Cache 的命名其实应该是: 48 KiB L1 D-Cache → 192 KiB L1.5 D-Cache 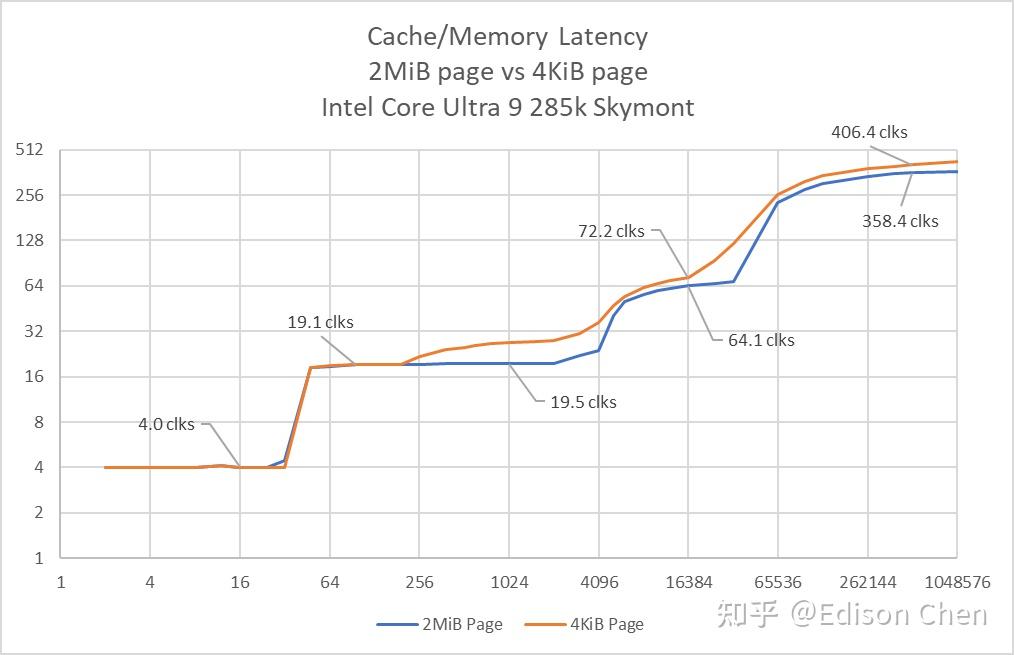
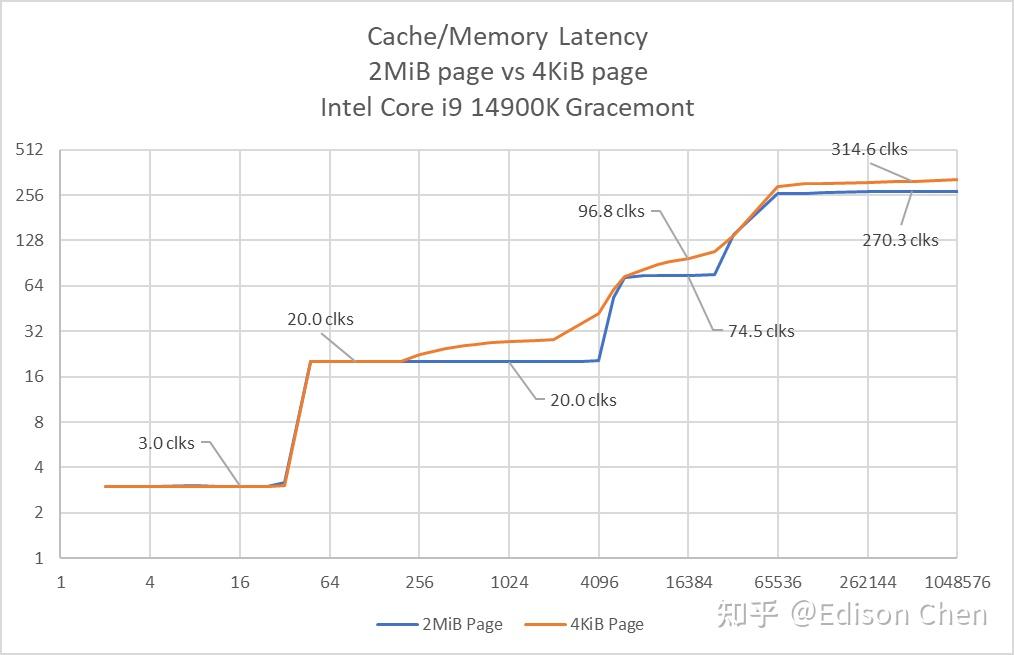
在 E-Core 方面,Skymont 的 L1D 时延增加了 1 个周期,L2 减少了 1 个周期。 在进入内存阶段后,Arrow Lake 的访存时延都有所增加,这可能是 Arrow Lake采用 chiplet技术导致的。 TLB 特性TLB 是用于提供物理、虚拟转址缓存用的,每项对应一个 page size 的地址映射,页面大小对 TLB 效率有非常重要的影响,目前的 Linux 默认 page size 是 4KiB,此时一个 TLB 项对应的就是一块 4KiB 大小的内存。更大的 page size 有利于提高 TLB 命中率,但是通常也会导致内存“碎片“较多造成内存空间浪费。 TLB 对系统性能非常重要,当年 AMD 基于 K10 的 Phenom B2 处理器就发生了 TLB 错误,AMD 弄了一个 bios 修正,其实就是禁用了 TLB,这导致 Phenom B2 在不同应用中的性能出现下降,特别是在 WinRAR 这类访存密集型、高度依赖 TLB 的应用,性能会从 1.3 MiB/s 急速下跌到 367KiB/s(Anandtech 测试数据)。 由此可见 TLB 对性能的影响。 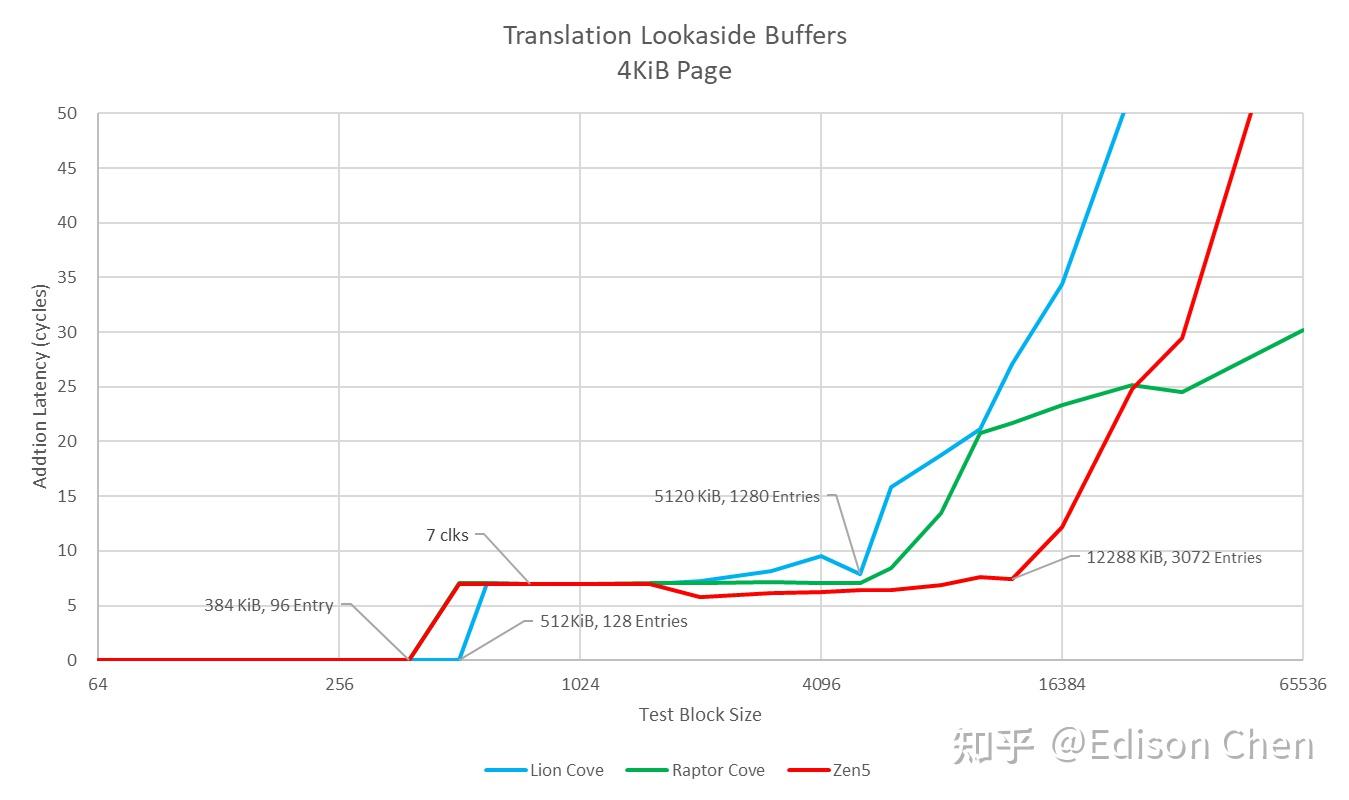
从测试结果来看,Lion Cove 的 L1 DTLB 大小是 128 项,L2 DTLB 应该是 1280 项。 Zen5 和 Raptor Cove 的 L1 DTB 均为 96 项,Zen5 的 L2 DTLB 是 3072 项。 三款微架构的 L1 DTLB 命中缺失后会产生额外的 7 个周期时延。 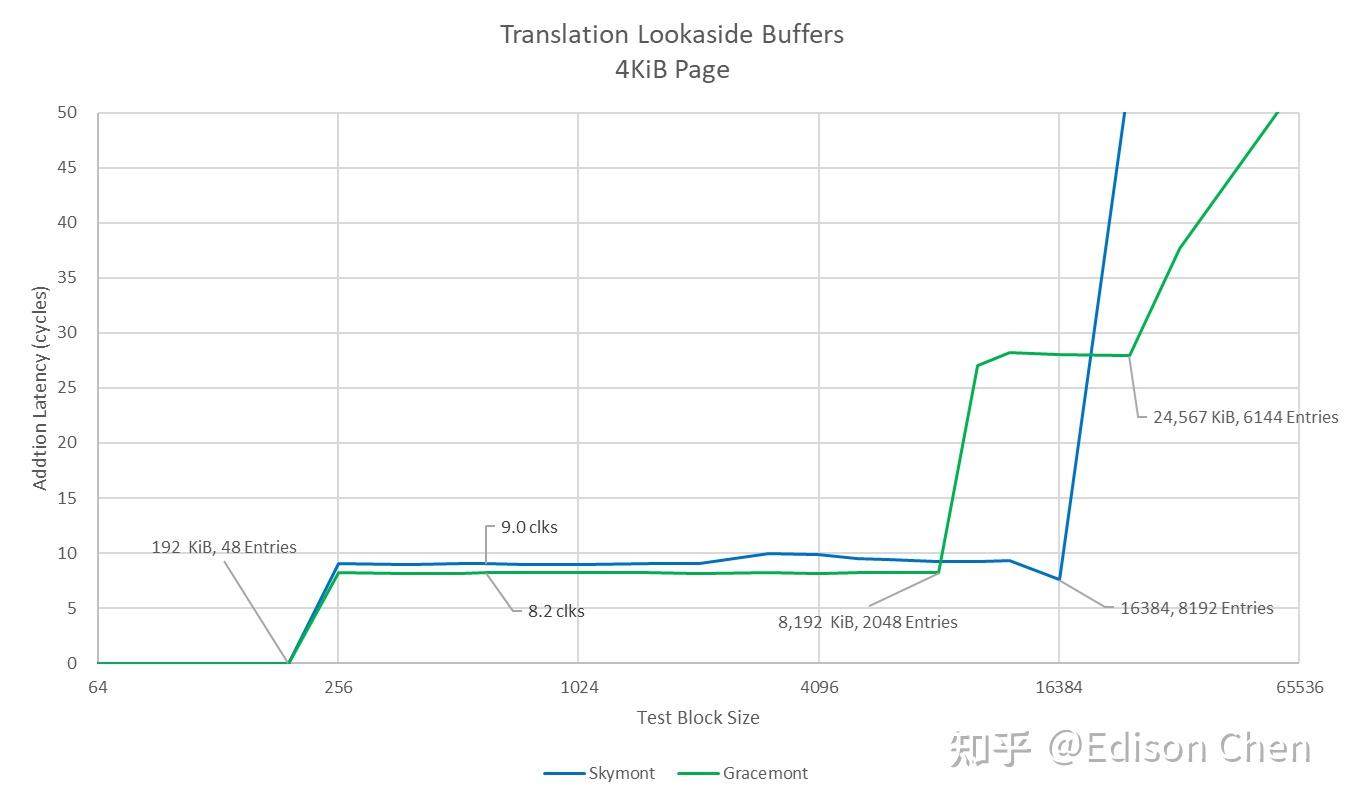
Skymont 和 Gracemont 的 L1 DTLB 都是 48 项,L1 DTLB 命中缺失后,Skymont 的时延惩罚是 8 个周期,Gracemont 是 9 个周期,Skymont 的 L2 DTLB 大小是 8192 项,比 Gracemont 的 2048 大三倍。 指令吞吐与时延峰值吞吐和重命名单元吞吐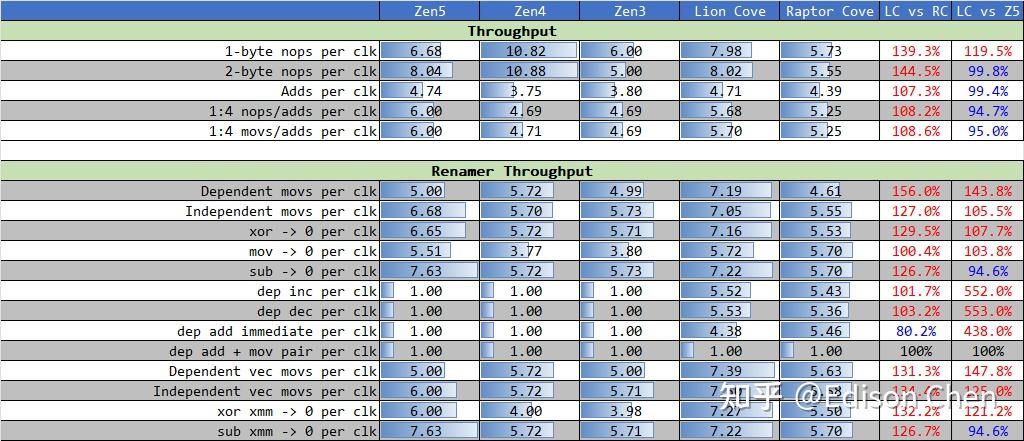
实测 Lion Cove 的峰值指令吞吐为每周期 8 条 NOP 指令,双字节 NOP 指令比 Raptor Cove 每周期多大约 2.5 条指令。 在 1:4 形式的简单指令组合下ALU 吞吐能力为每周期 6 条指令。 Renamer 吞吐测试的是乱序流水线中寄存器重命名单元的性能,该单元的作用主要是消除指令之间寄存器相依问题,从而充分利用执行工位的指令吞吐资源。 其中,还有 dep 的测试项目都是无法实现寄存器重命名的,其余指令则是可以执行寄存器重命名处理。 除了 mov->0、dep dec、dep inc 和 dep add immediate 外,Lion Cove 的 Renamer 能力都比 Raptor Cove 有不同程度的提升,提升幅度在 25% 到50%。 在寄存器重命名能力上,Lion Cove 有非常大的提升,符合 Intel 资料里提到的 Renamer 能力为每周期 8 条指令的情况。 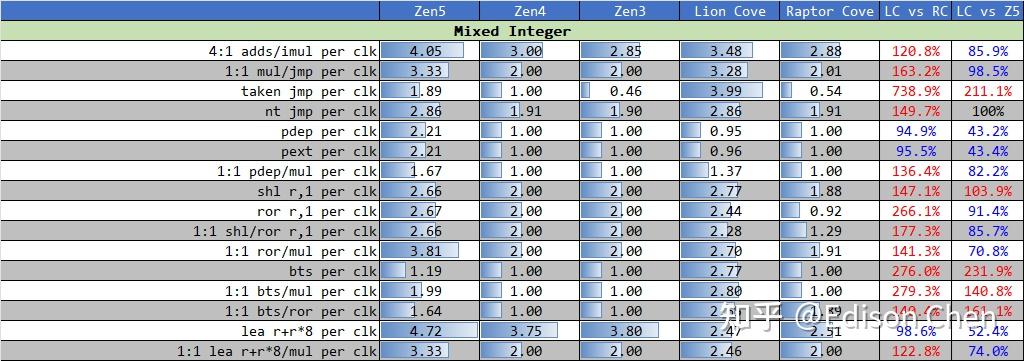
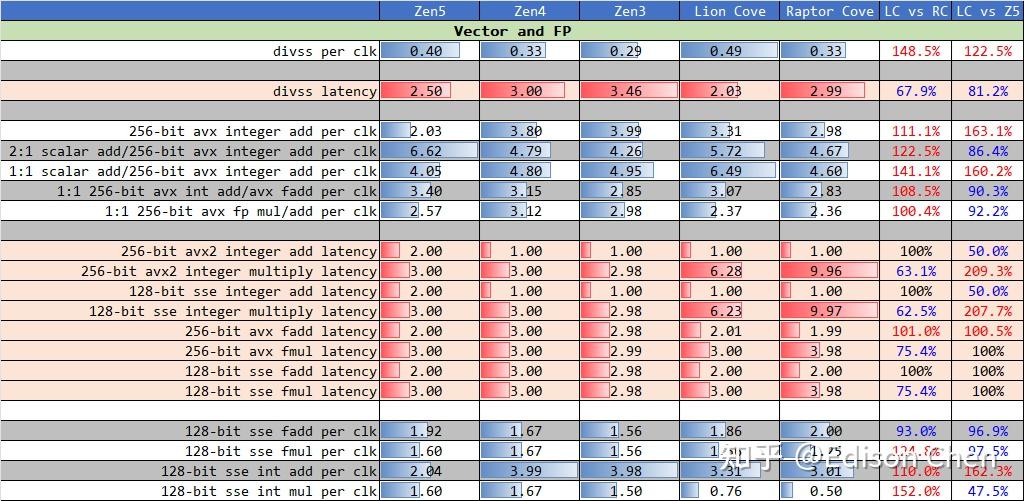
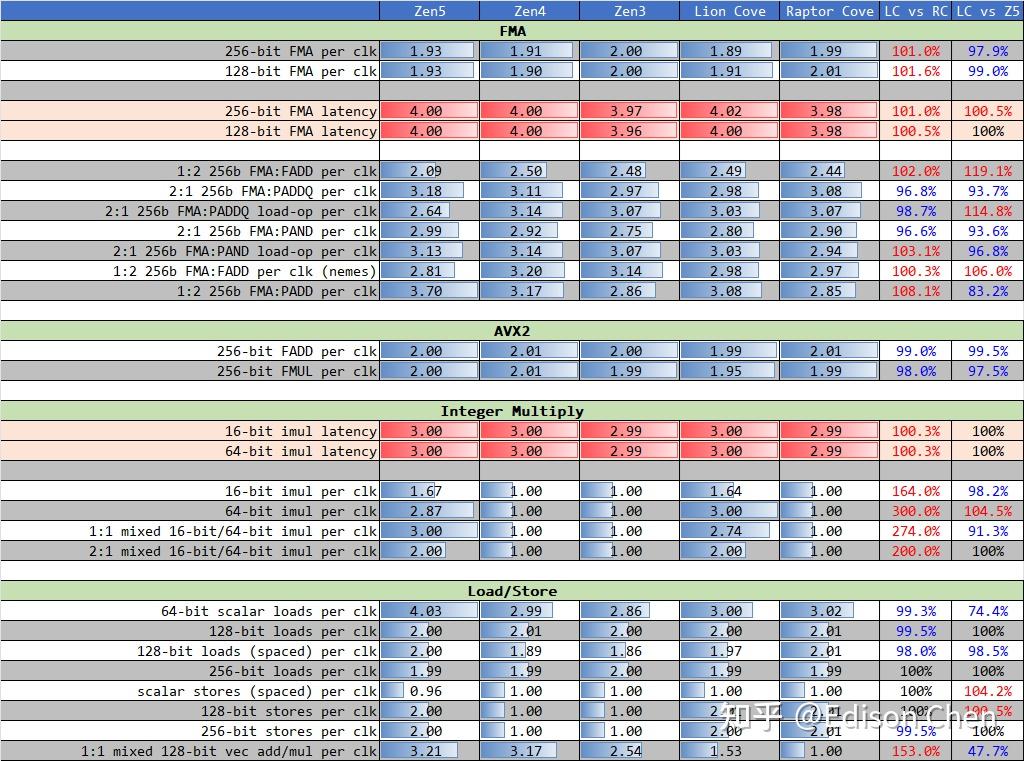
在访存单元或者说 LSU(Load/Store Unit)方面,Lion Cove 基本没啥提升,Load 单元并未如 ppt 说的那样具备三个 256-bit的样子,更像依然是两个。 整数乘法单元从之前的 1 个提升到了 3 个,这样就和 Zen5 差不多了。 流水线深度现代处理器都采用了多级工位设计,大家把这种多级工位设计成为流水线化或者管线化。 流水线深度和处理器频率延伸能力、分支预测失败惩罚有密切关系。 一般来说,流水线工位越细分,各个工位的时间片就越短,处理器的频率看起来越就越高,但是工位越多,分支预测缺失导致的性能损失也就越多。例如 5 级工位的流水线遇到分支预测缺失,可能也就是损失 5 个处理器周期,但是如果是 20 级流水线可能损失的 CPU 周期就会达到 20 个。 现在的内核流水线设计异常复杂,不同指令流向经过的流水线工位数可能是不一样的。 为了探测 Zen5 的流水线深度,我使用了多种代码来测试。 下表中的左侧是以伪代码方式提供分支程序测试片段,以第 7 个测试(Test 6)为例: Test 6, N= 1, 8 br, MOVZX XOR ; if (c & mask) { REP-N(c^=v[c-256]) } REP-2(c^=v[c-260]) 这段伪代码中包含了一个 MOVZX 内存载入操作指令,根据处理器的不同,它可能需要额外的 5 到 6 个周期(可能更少)来执行,在支持乱序执行、乱序 L/S 的处理器中,这个动作占用的流水线工位通常会被掩盖掉。 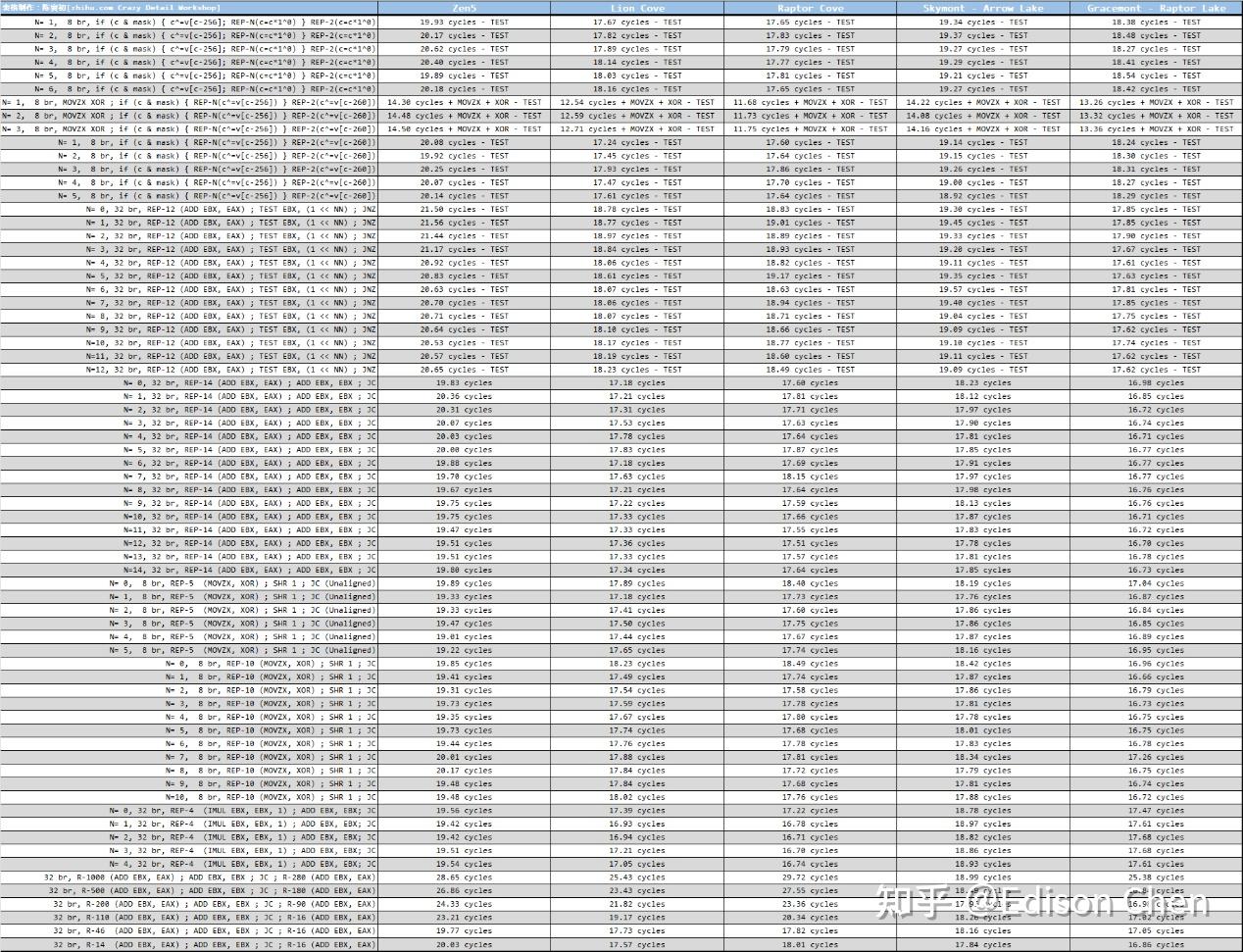
从测试结果来看,Lion Cove 的分支预测惩罚要比 Raptor Cove 略小,平均减少了大约 0.3 个周期,缩减的主要测试项目是第 64-69,时延分别降低了 0.5% 到 15%,这里的第 67 号测试开始在 Raptor Cove 上会出现 micro-Op Cache 溢出的可能。 以目前的测试结果来看 Lion Cove 和 Raptor Cove 的流水线深度深度差不多,前者在较大指令包下的较低惩罚可能是 micro-Ops Cache 较大带来的。 Reorder Buffer 和寄存器堆Lion Cove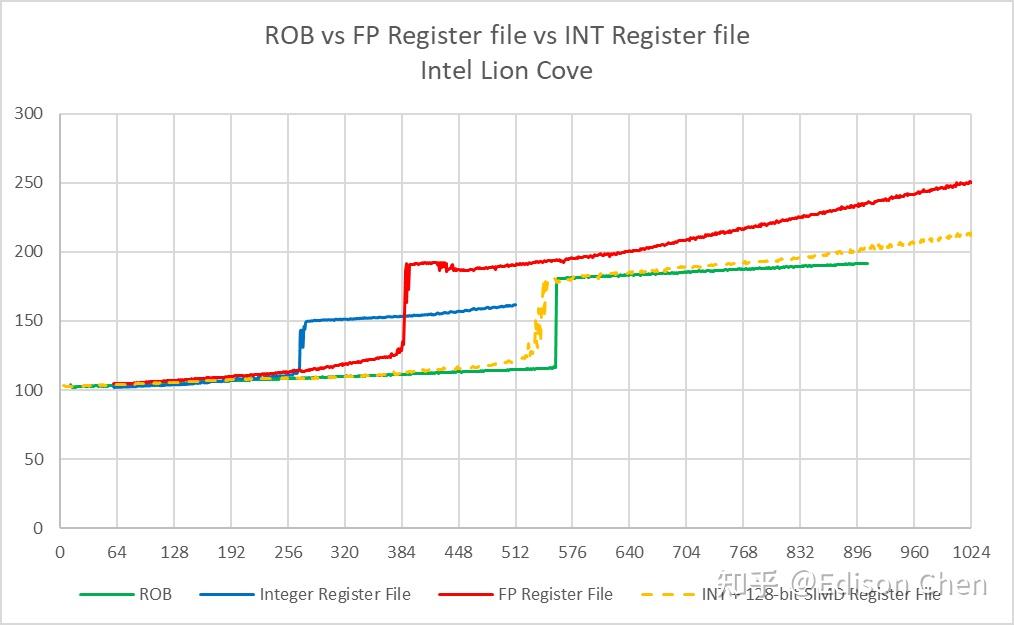
Raptor Cove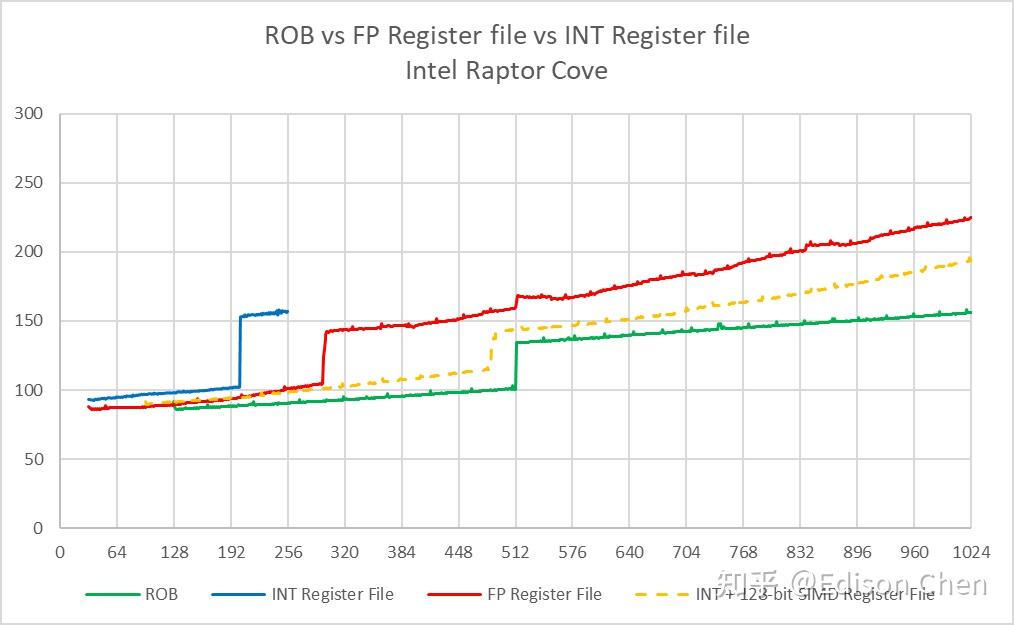
Zen5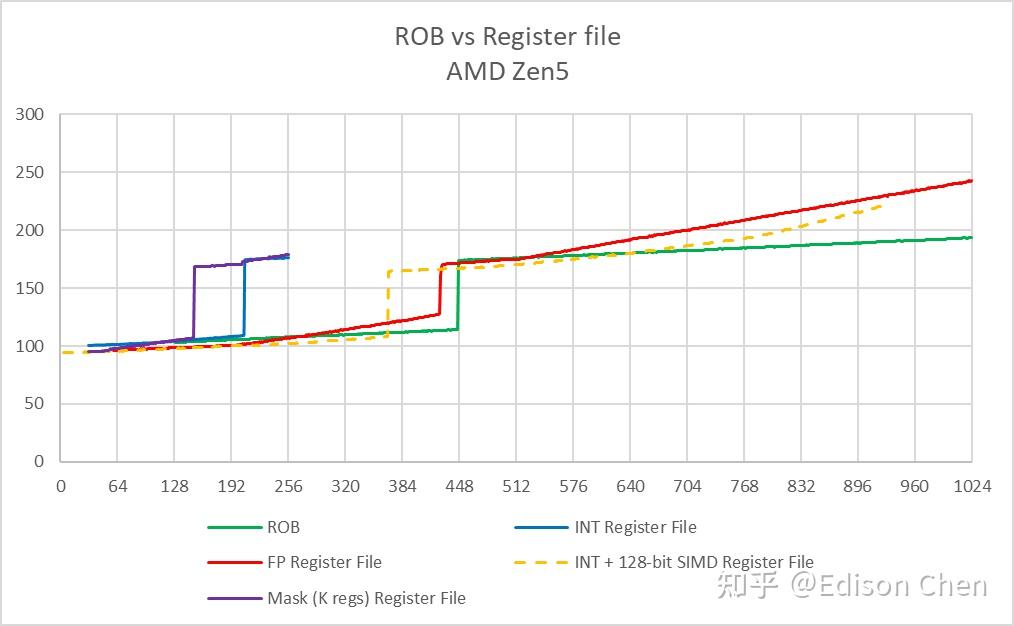
Skymont (Arrow Lake E-Core)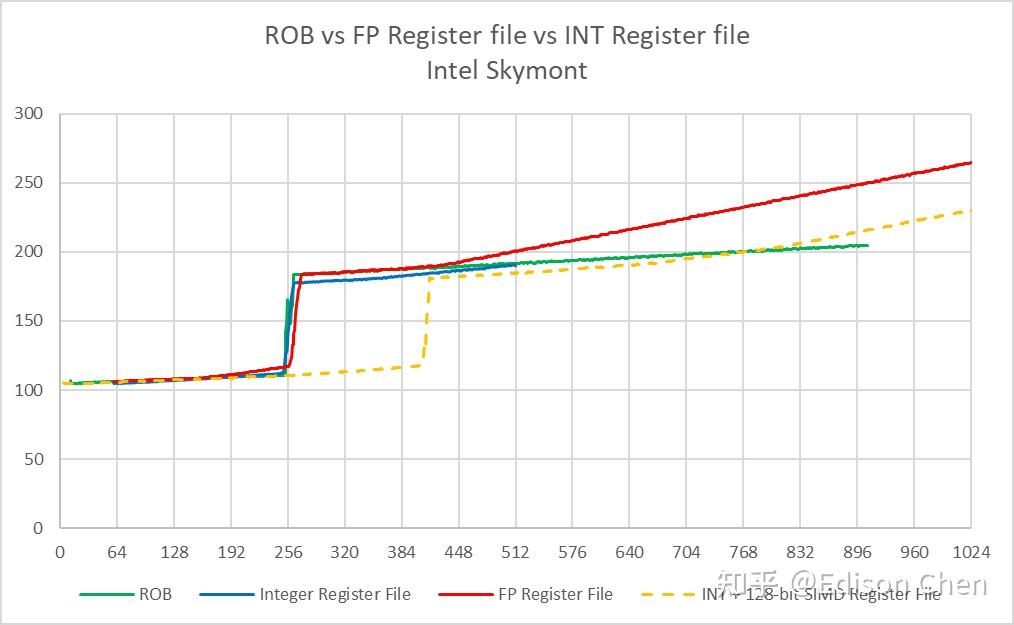
Gracemont (Raptor Lake E-Core)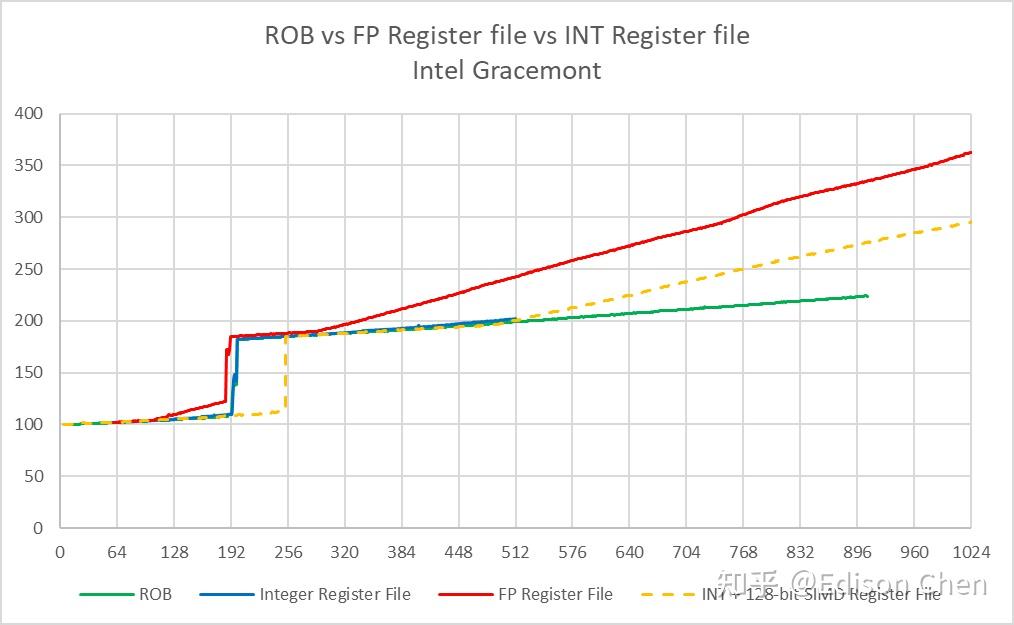
ROB 或者说重排序缓存是 CPU 乱序执行流水线上用于保存临时中间结果的缓存,它可以确保计算结果能按照原顺序写入到寄存器堆里,即使指令乱序执行,处理器依然可以在发生异常或者分支预测错误时恢复到正确的程序状态,它的大小意味着处理器流水线上有多少个待执行指令可以供指令分发单元选择。 按照 Intel 的资料,Lion Cove 的 ROB 大小为 576,实测在 557 项的时候发生明显跃变,这意味着在 Lion Cove 上大约有 19 项是被保留了,相较而言 Raptor Cove 则是和官方资料一样是在 512 项处发生明显跃变。 Skymont 的 ROB 大小实测为 256 项,Gracemont 是 192 项,两者的 ROB 都未能完全覆盖整数+向量的寄存器堆大小,这意味着它们的执行资源有可能无法得到充分使用。 Load/Store 单元资源Load 队列大小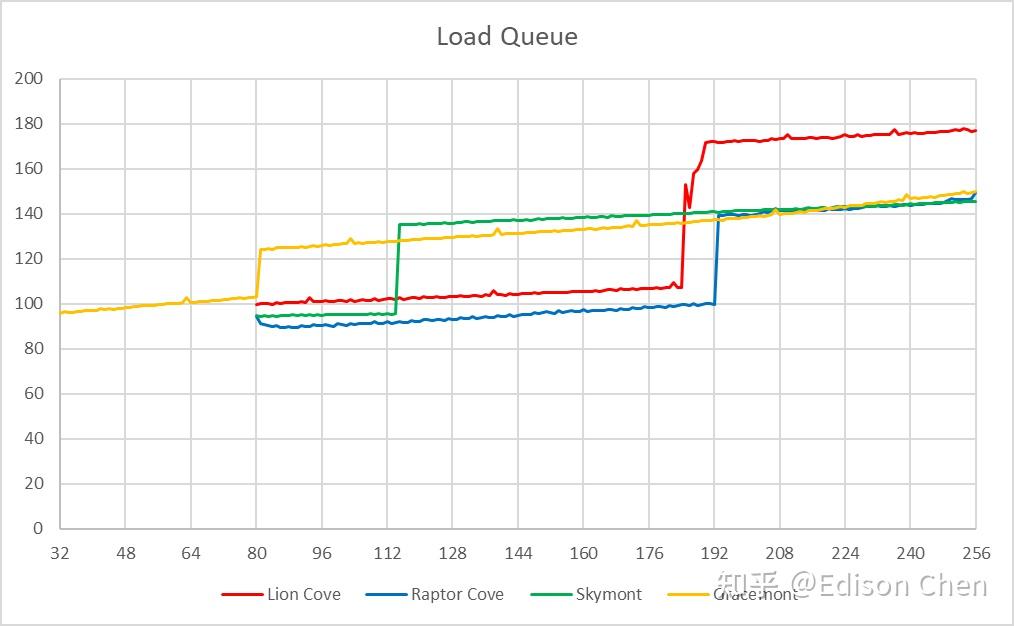
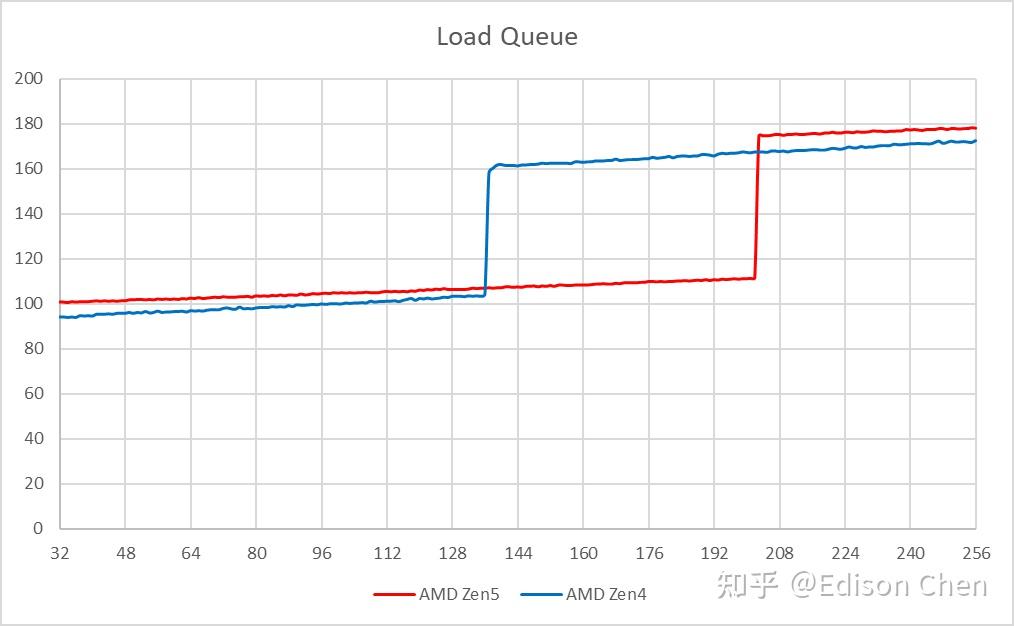
从测试结果看: Lion Cove 的 Load 队列是 184 项,Skymont 是 114 项; Raptor Cove是 192 项,Gracemont 是 80 项; Lion Cove 的 Load 队列比上一代的 Raptor Cove 少了 8 项,虽然不是什么大问题,只是出现倒退这点比较罕见。 Store 队列大小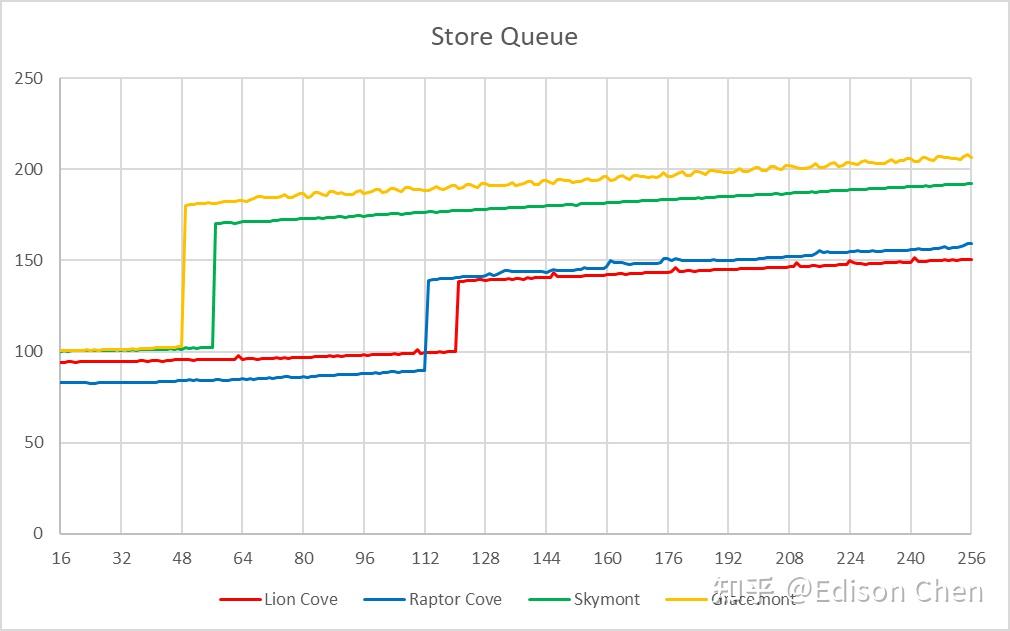
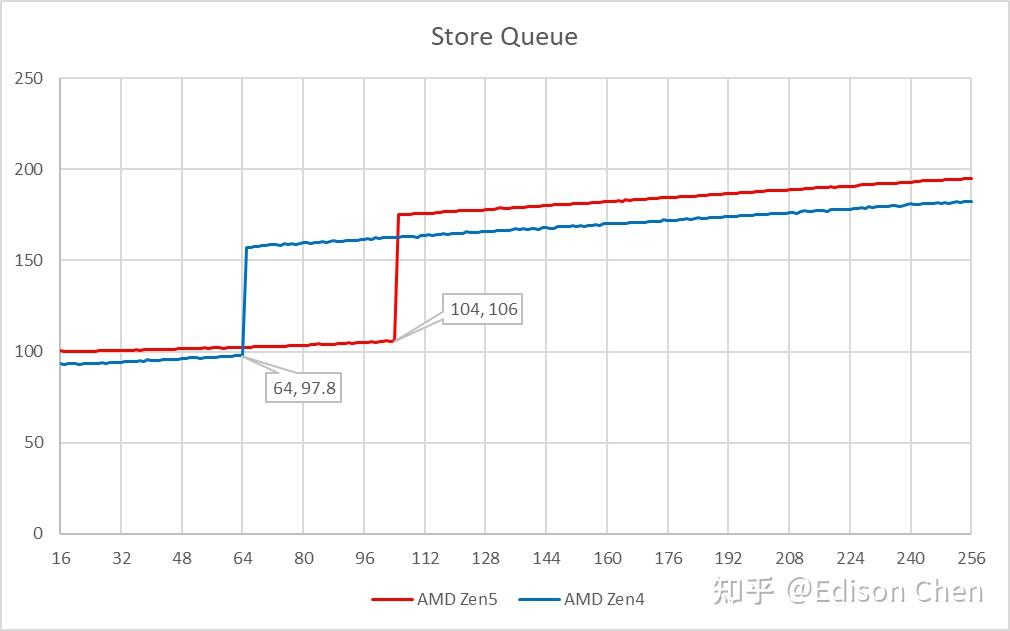
Lion Cove 和 Skymont 的 Store 队列大小都有提升,但是提升不大: Lion Cove:120 项(Raptor Cove 是 112 项); Skymont:56 项(Gracemont 是 48 项)。 分支预测直接分支预测分支预测是乱序执行处理器非常重要的组成,最早好像是 IBM 的分立元件处理器 360/91 上实现,当年 Cyrix 的 5x86 可能是第一款号称支持动态分支预测的 x86 处理器,但是该功能居然在最终版本被禁用,同年稍后推出的 Pentium Pro 则应该是真正将动态分支预测落地实用的 x86 处理器。 分支预测常见的类型有 Direction Prediction 和 Indirection Prediction,前者最常见的有 if else,其跳转的目标是确定的(跳转的方向 A 或者 B 设定好的),而后者虽然也有 if else 等形式,但是跳转的方向则是不确定的(A 和 B 的位置是不确定的)。 以生活中的例子来举例。 例如你在早上出门的时候要判断是否带雨伞,如果天气预报说下雨,那你就会带雨伞,否则不带。对这种分支做预测,就是方向预测。 如果你要在一个大型商场找某个特定的商店,虽然知道商店的名字,但是商店位于哪里你本人并不知道,你需要查找商场地图才能获知。对这种分支做预测,就是间接预测。 我们前面的测试用了 100% 无法成功预测的指令和可以 100% 成功预测的指令来测量分支预测缺失导致的惩罚周期数来估计流水线深度,下面让我们对这部分进行更深入的测试。 首先是直接分支预测。 Lion Cove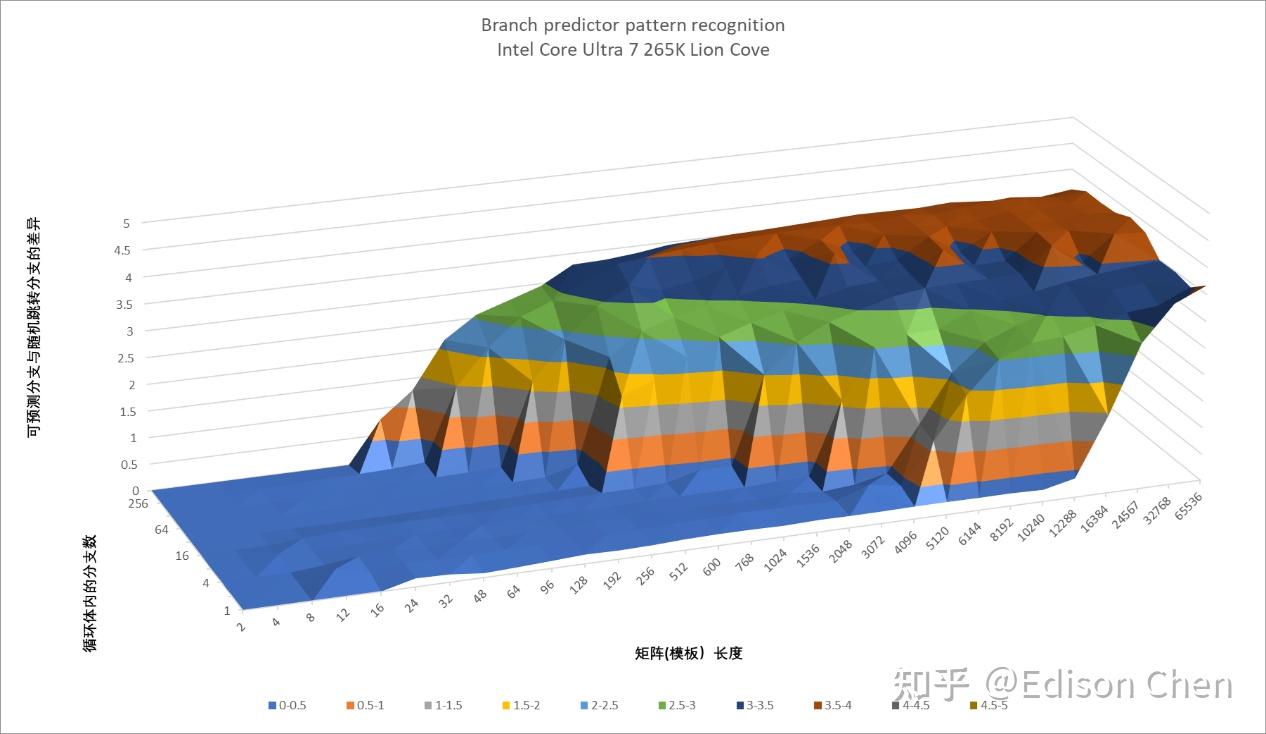
Raptor Cove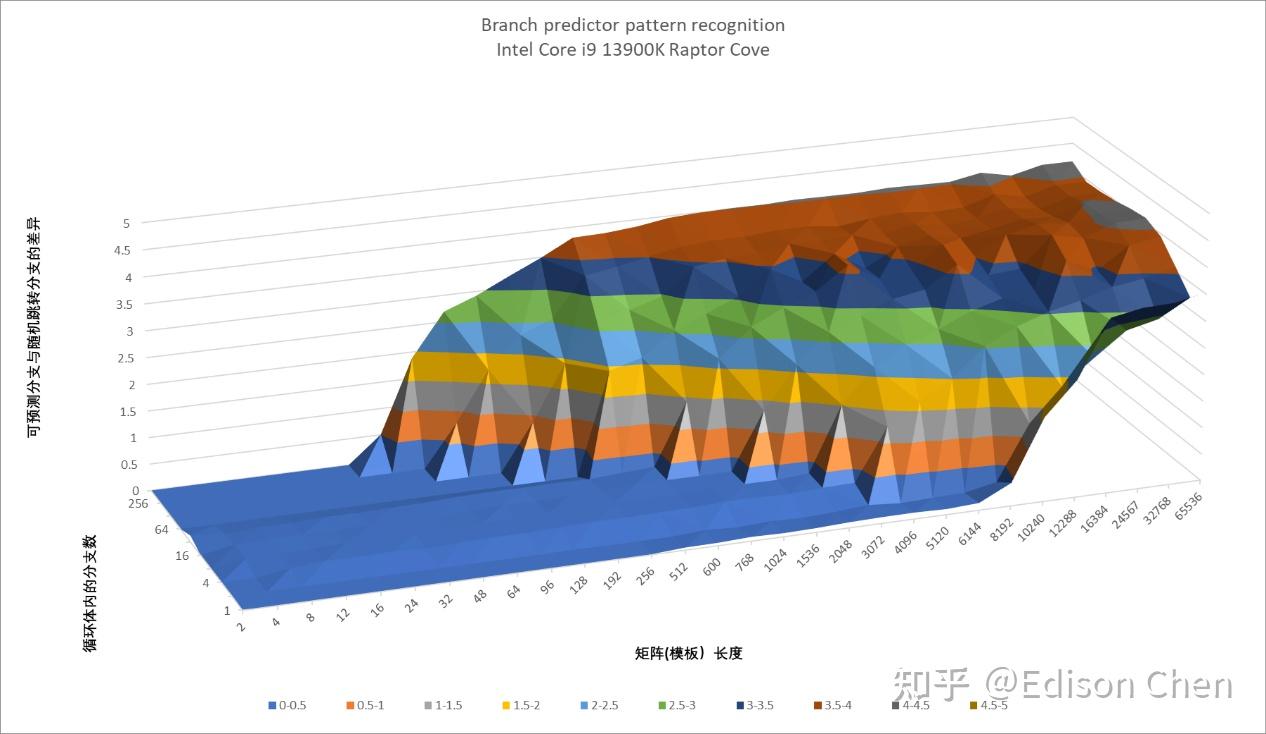
Zen5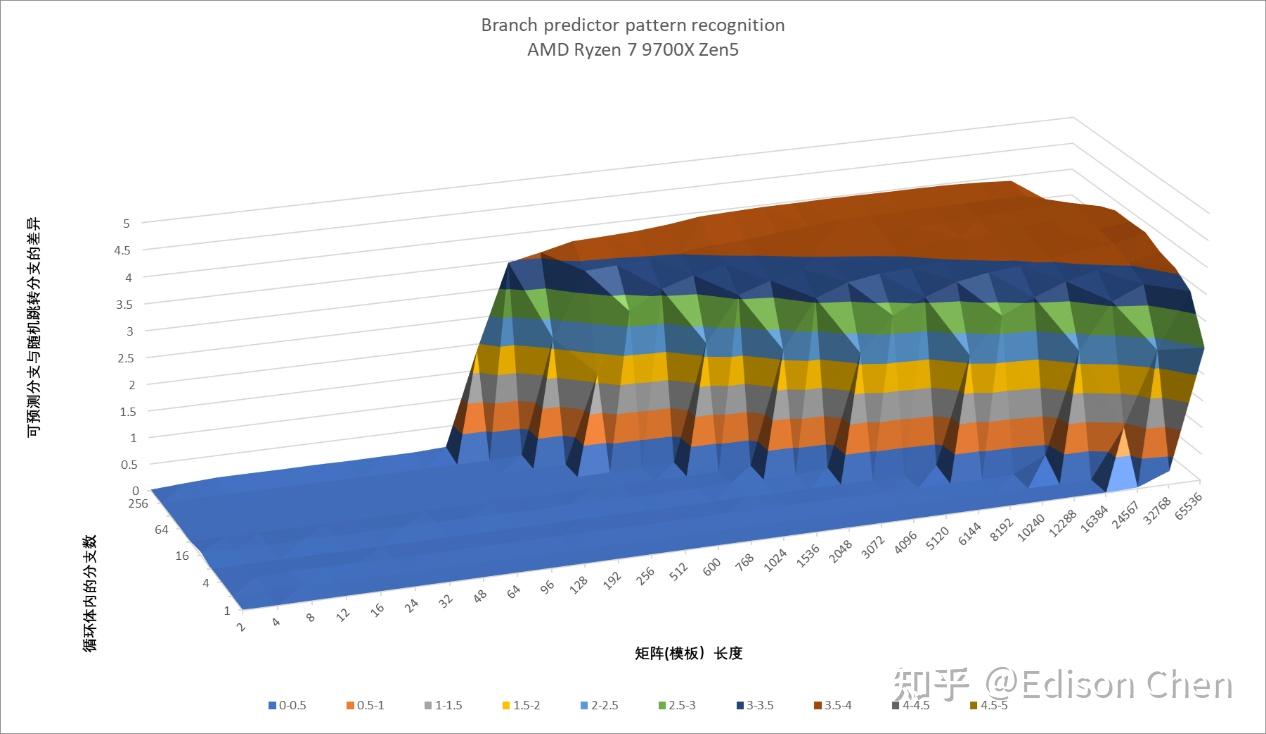
Skymont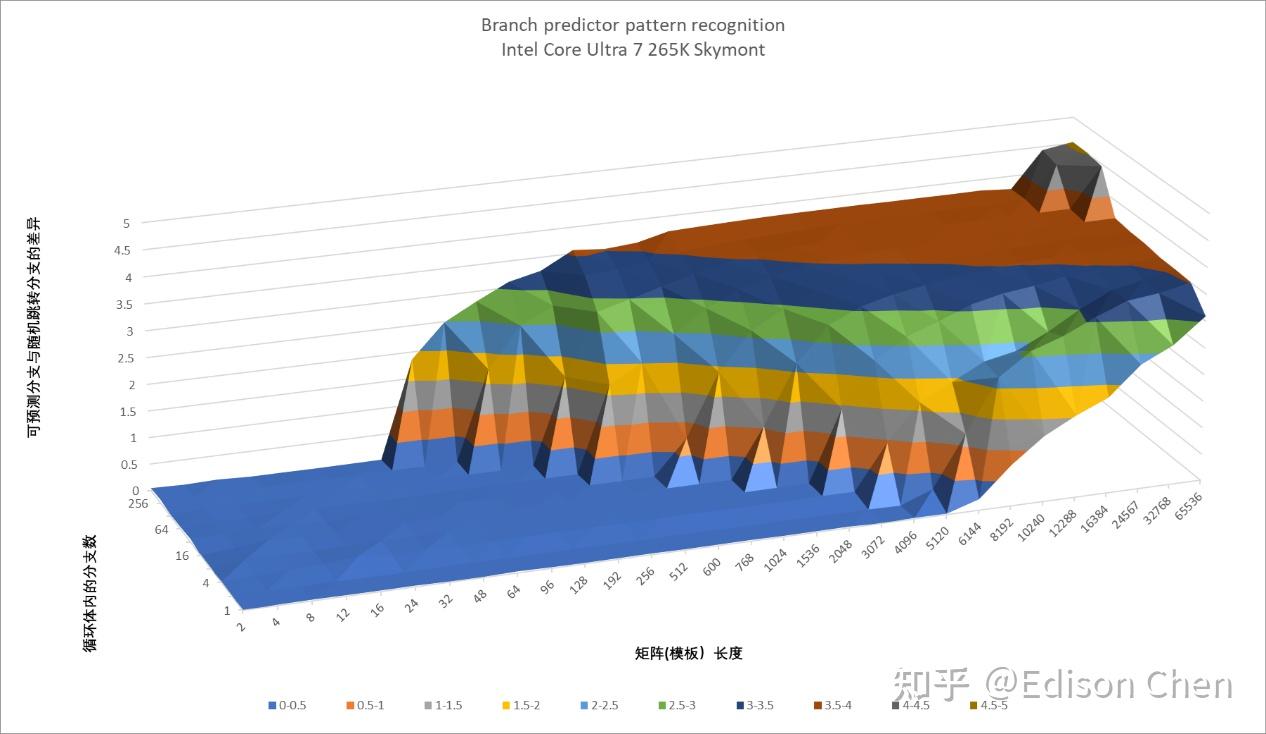
Gracemont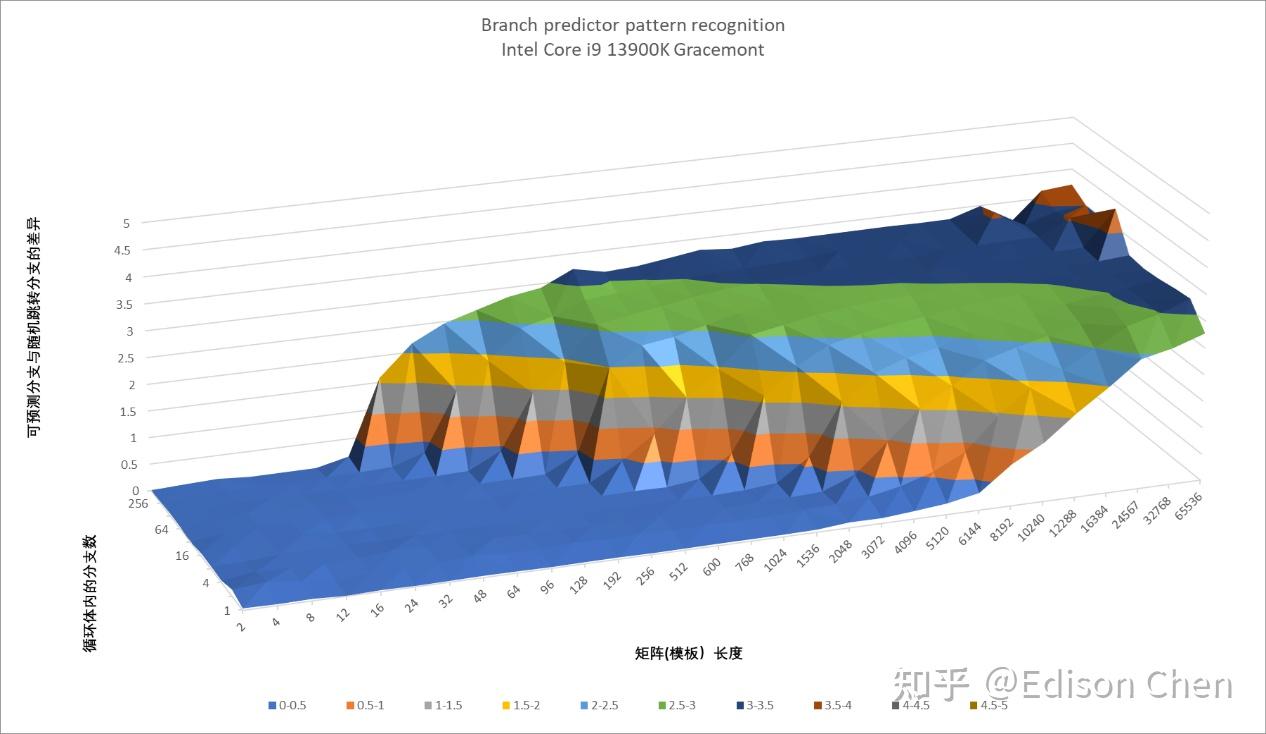
从测试结果看,Lion Cove 在直接分支上的虽然有变化,但是既有进步的一面,也有退步的,可以认为实际上维持着原来差不多的水平。 Skymont 和 Gracemont 相比主要是大量分支的时候分支预测能力更强了。 间接分支预测Lion Cove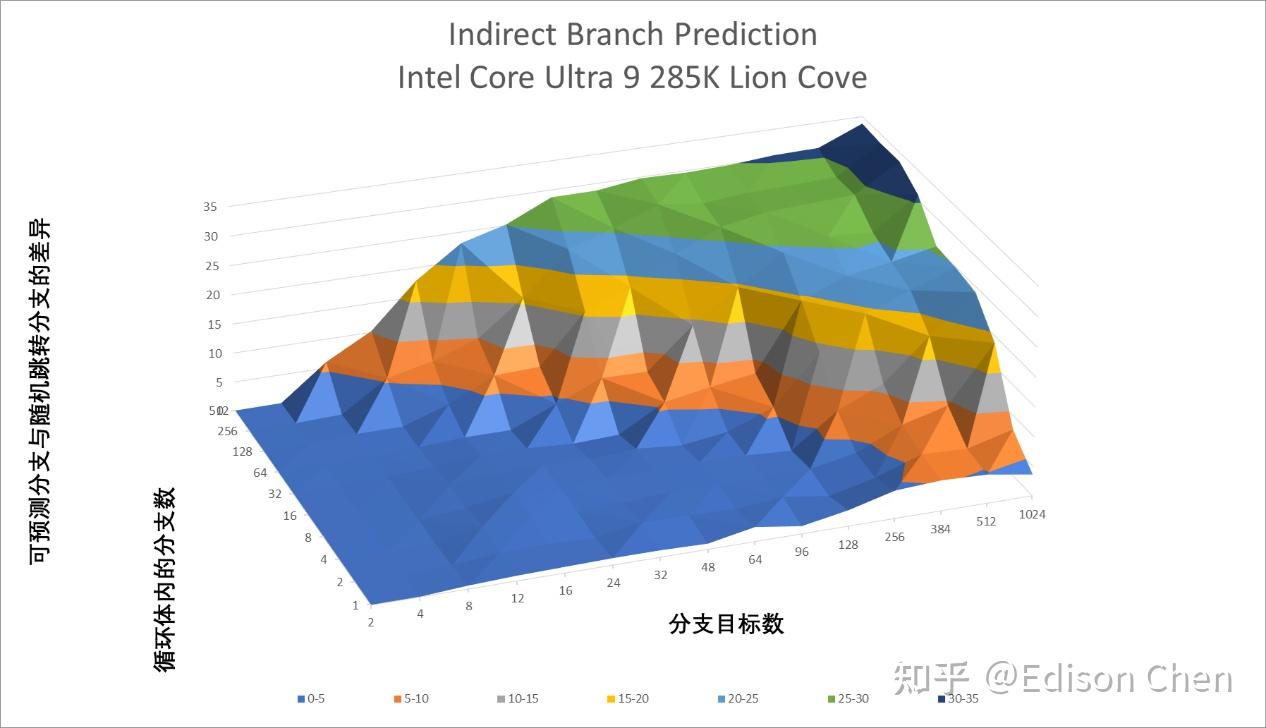
Raptor Cove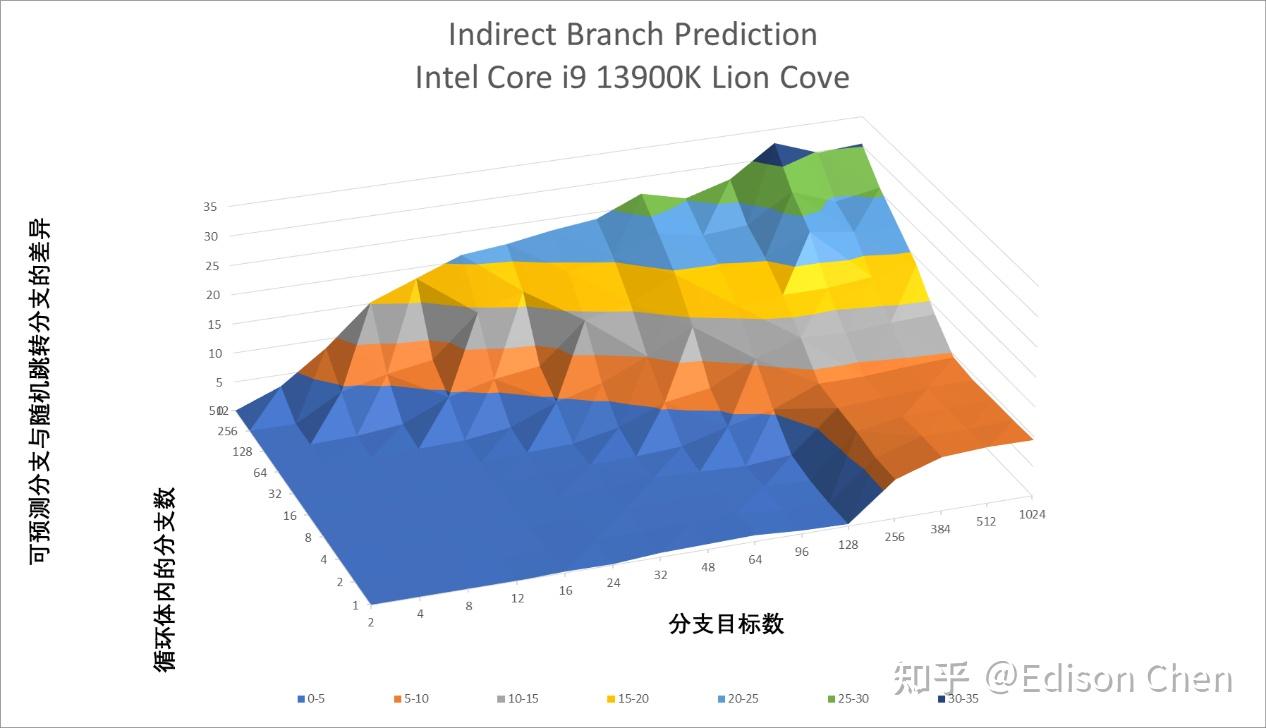
Skymont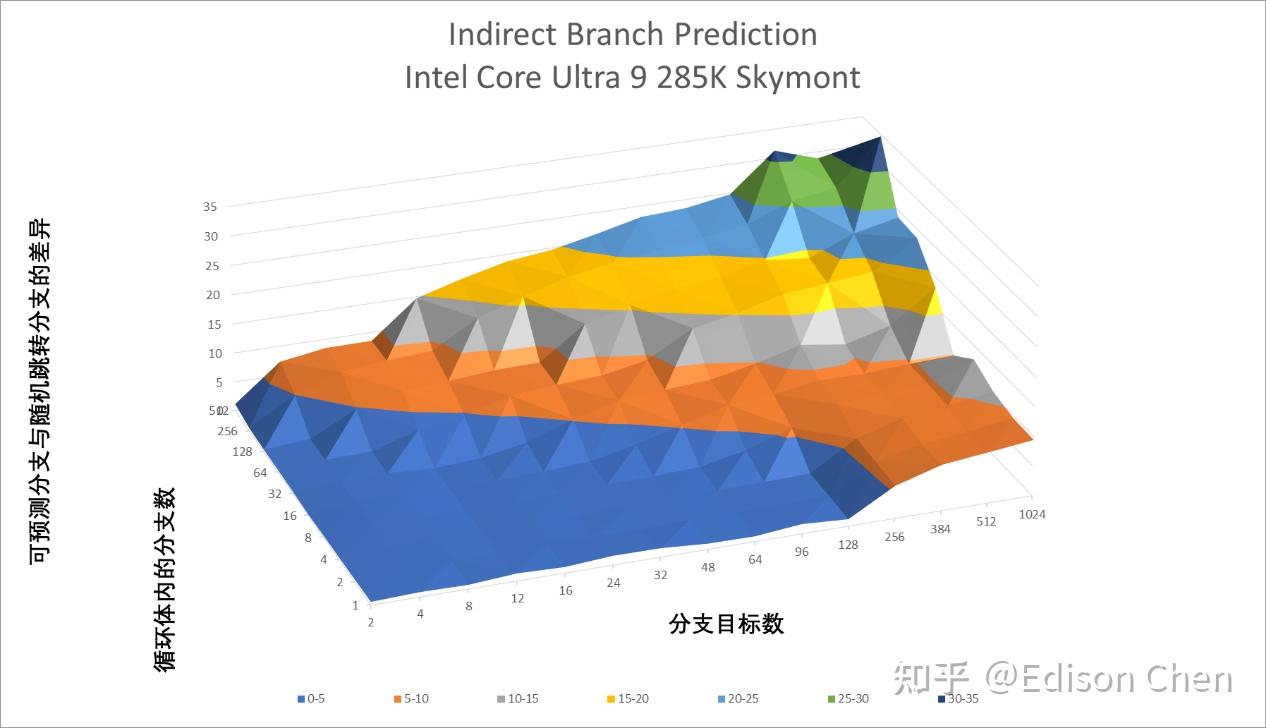
Gracemont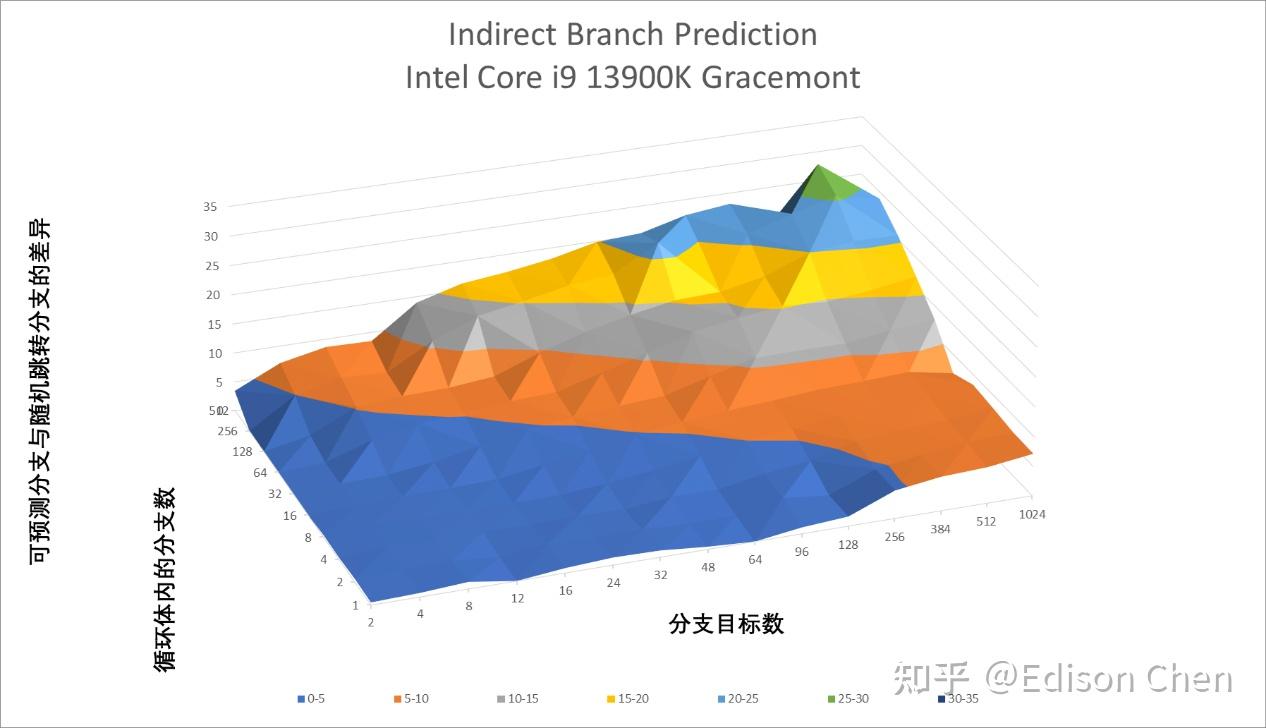
间接分支预测的情况也差不多,变化不大。 Cache 一致性性能/核间时延Arrow Lake(Intel Core Ultra 9 285k)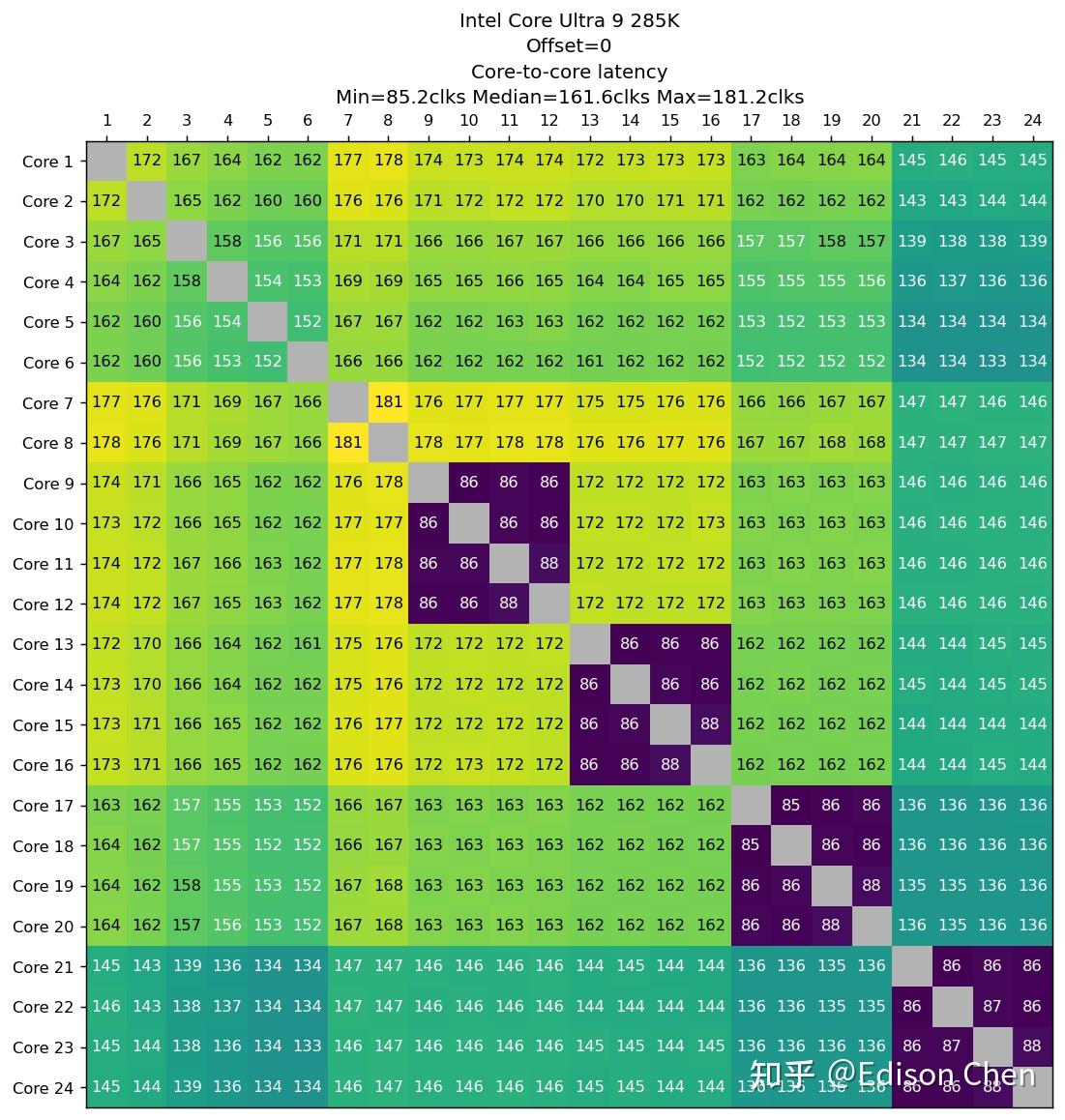
Raptor Lake(Intel Core i9 13900K)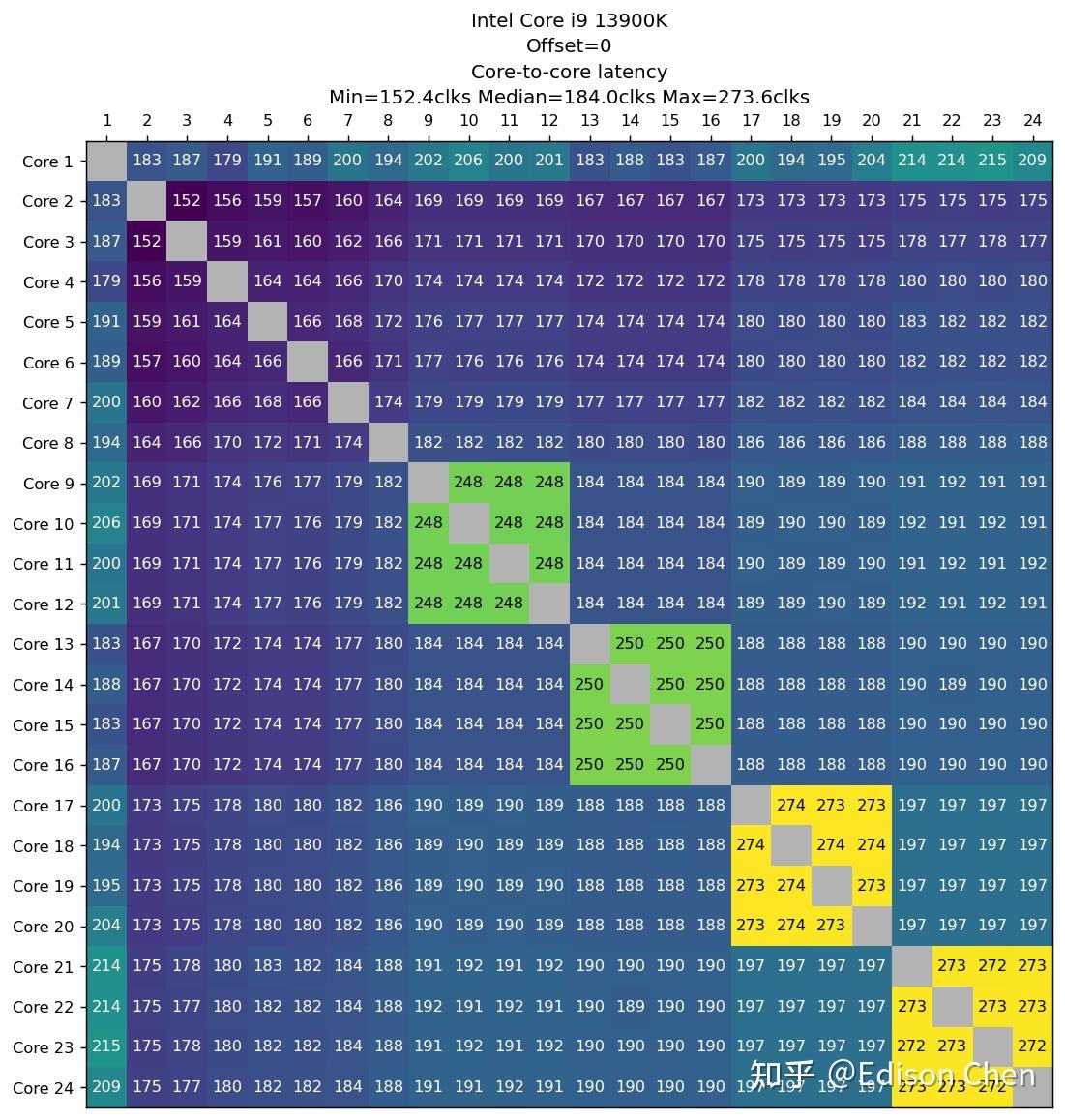
Zen5(Ryzen 9 9950X)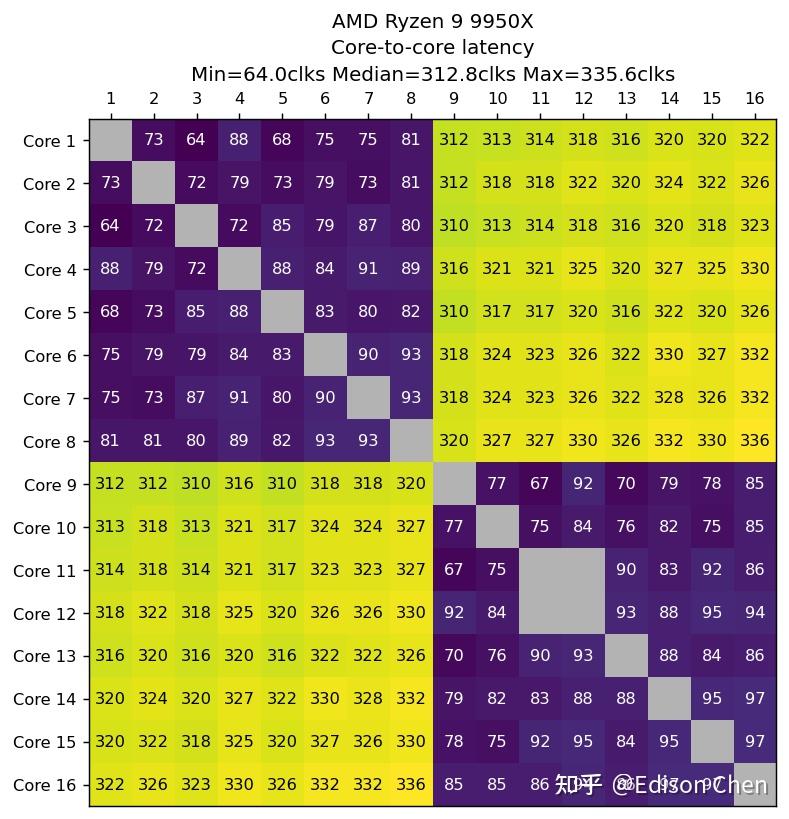
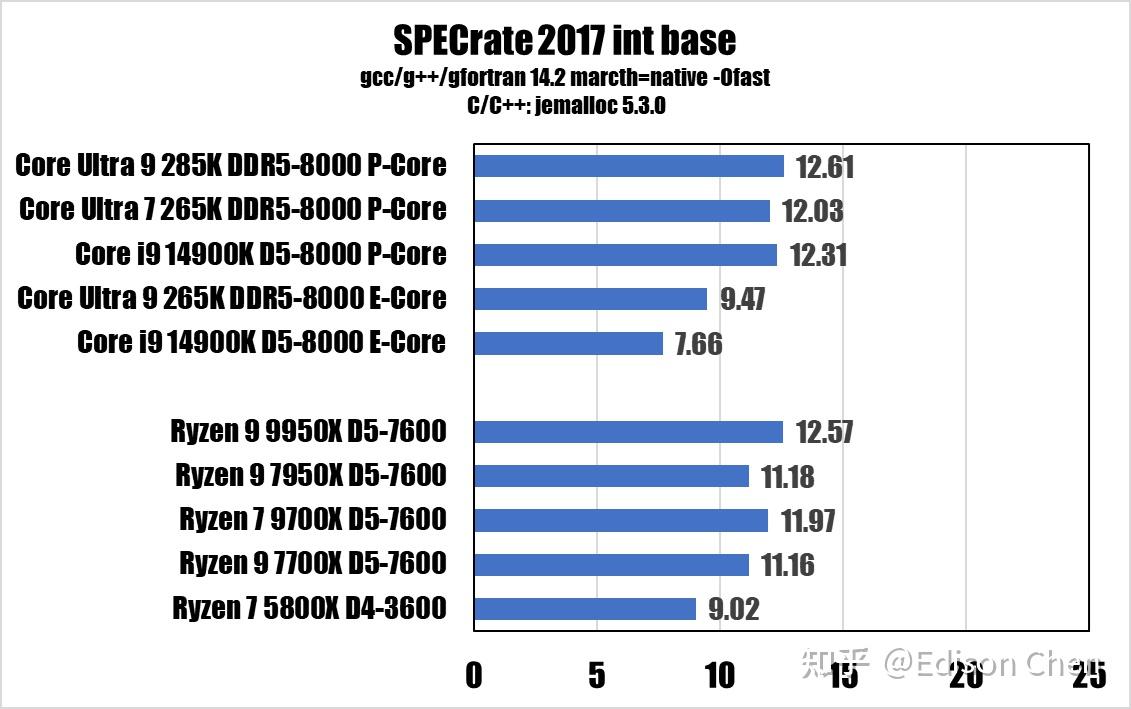
在多处理器系统里,各处理器如果需要更新某块内存里的数据,就需要同时更新各处理器相应缓存里的对应数据,在有些情况下有可能会性能瓶颈(虽然对于桌面用户来说极为罕有),Cache 一致性性能测试就是为了测试 CPU 的性能表现。 上面的测试都是在所有内核均锁定 4GHz 下完成并转换为周期为单位,便于对比核间时延。 由于都是一个 die 内,所以 285K 的内核在进行核间数据更新的时候可以在 L3 乃至 L2 Cache(E-Core 簇内)内完成。而 13900K 的 E-Core 需要跑到 L3 Cache 更新核间数据,所以 E-Core 簇内核间内时延较高。 285K 的核间时延无论是 P-Core 还是 E-Core 都要比 13900K 更好。 9950K 的情况大家也都应该知道,它有两个 CCD,CCD 之间的时延还是比较可观。 SPEC CPU2017 性能测试CPU 2017 是非盈利机构 SPEC(标准性能评估公司)推出的 CPU 性能评估套件,SPEC 成立于 1998 年,会员包括 Intel、AMD、IBM、DELL、联想、华硕、技嘉等业界大公司,每隔大约 10 年就会推出一版新的 CPU 性能评估套件,CPU 2017 是该机构在 2017 年推出的,是所有处理器、电脑厂商做处理器性能评估的最重要手段之一(如果不是使用上有一定门槛,上面这句话的“之一”是可以省略的)。 SPEC CPU 的特点是由各个机构提供实际应用的源码,它的每一个子项目其实都是源自真实应用修改而来,其修改主要是针对可移植性和遵循的语言标准,例如 x264 的真实版本采用了大量的汇编代码,但是这样的形式不利于移植到不同指令集架构上测试,因此 CPU 2017 中的 x264 采用的是纯 C 语言版本。 和上一版本 CPU 2006 相比,CPU 2017 的代码已经全面更新,虽然依然使用 C/C++ 和 Fortran,但是相对以前的版本来说,已经变成了多语言的大混装。Fortran 语言同时出现在浮点和整数测试集,而非像以往那样只出现在浮点测试集。 CPU 2017 的规则更加严谨,speed 测试集允许使用 OpenMP 多线程处理,主要测试较大数据集和较大访存压力下的单任务多线程性能,而 rate 测试集则只允许单线程,禁止自动并行化,但是允许以多任务的方式跑多个 rate 测试,目的是测试吞吐率,单个 rate 任务的访存压力要比 speed 小很多。 不过 speed 测试集也不是全部项目都支持多线程,只有浮点密集型的 fpspeed 所有项目支持多线程,整数密集型的 intspeed 10 个子项目中只有最后的 657.xz_s(数据压缩)是支持多线程的。 这样的规则让以往 CPU 2006 以及更早版本中常见的编译器自动并行化“优化”手段被禁止使用,减少了测试结果的混乱(测试如果使用了编译器自动并行化后,实际上变成了编译器比拼),提高了可比性。 测试使用了 gcc 14.2 编译器。 编译开关为 -march=native 和 -Ofast,-march=native 表示采用编译器预设的微架构识别信息来选择最佳化设置,对 Arrow Lake 架构的处理器来说,在 gcc 14.2 上面 native 就是 arrowlake-s(也就是说,-march=native 此时等于 -march= arrowlake-s)。 性能得分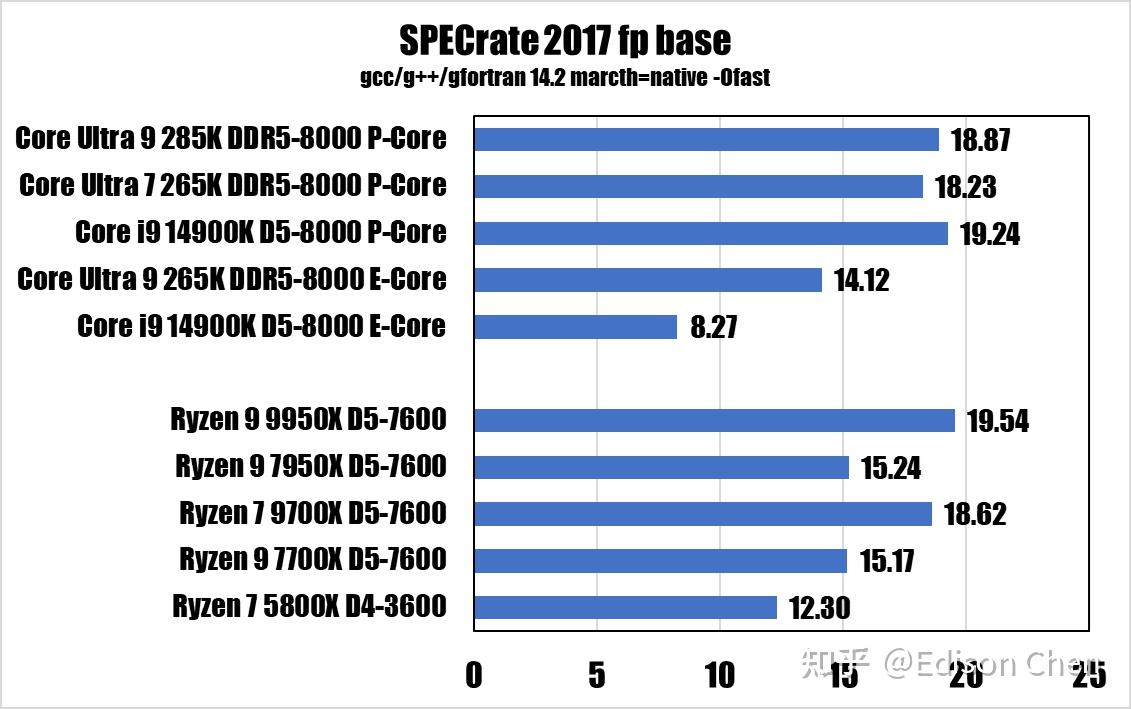
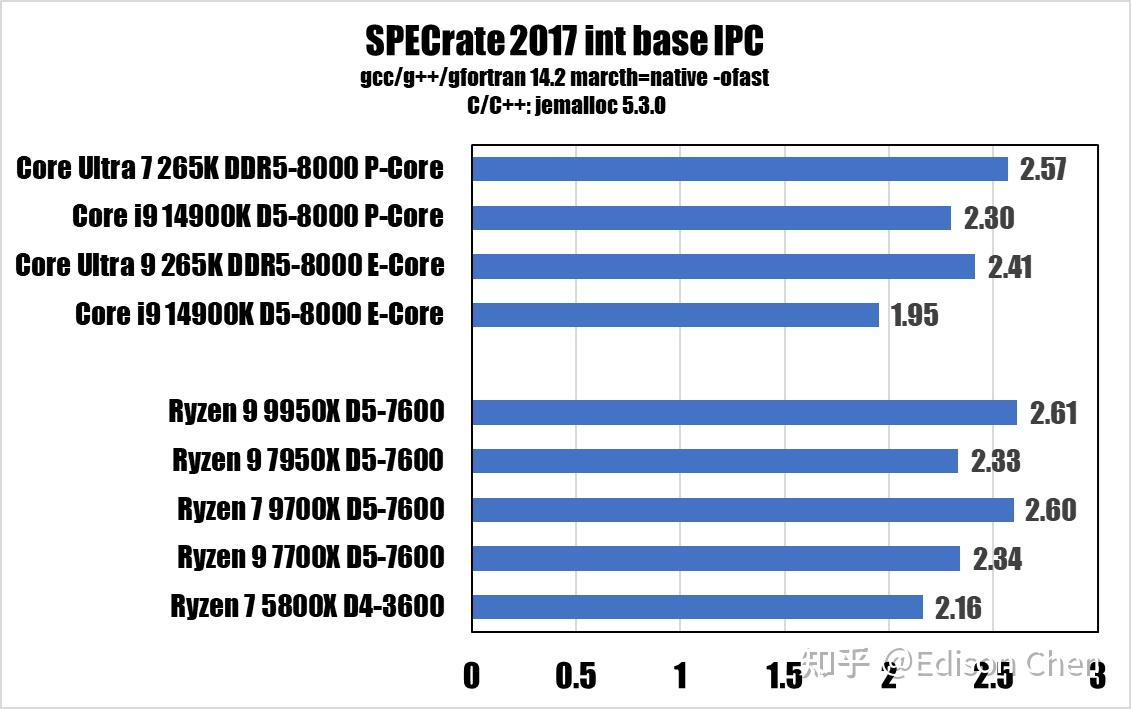
每周期指令数(IPC)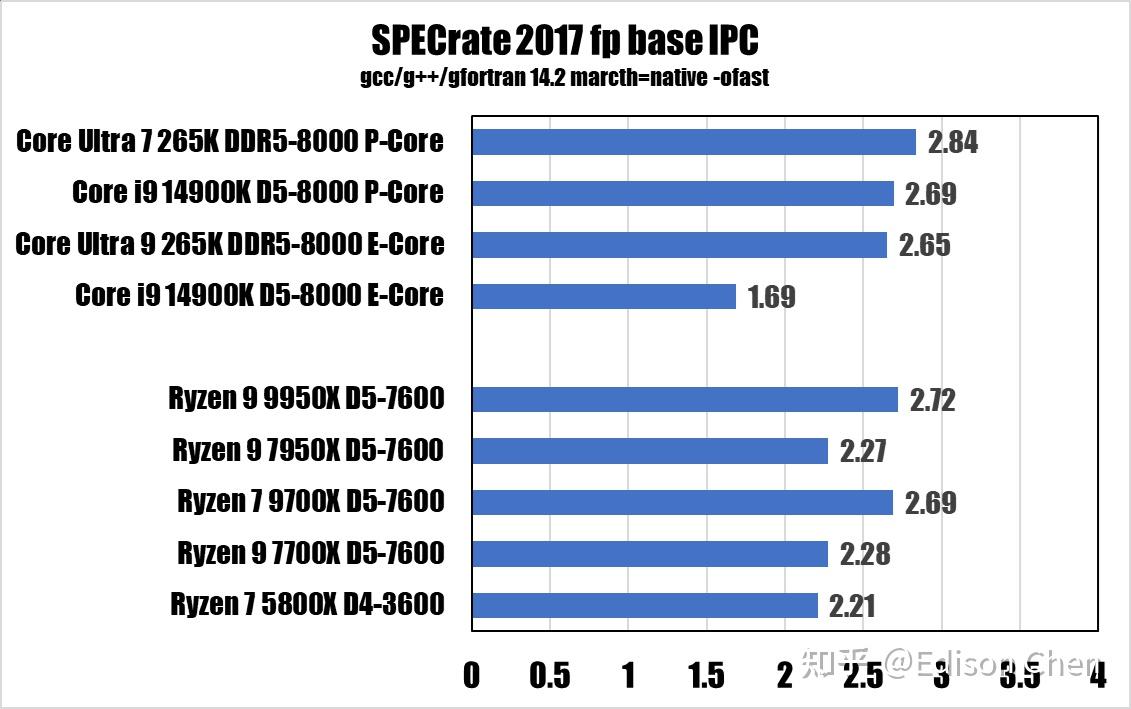
能耗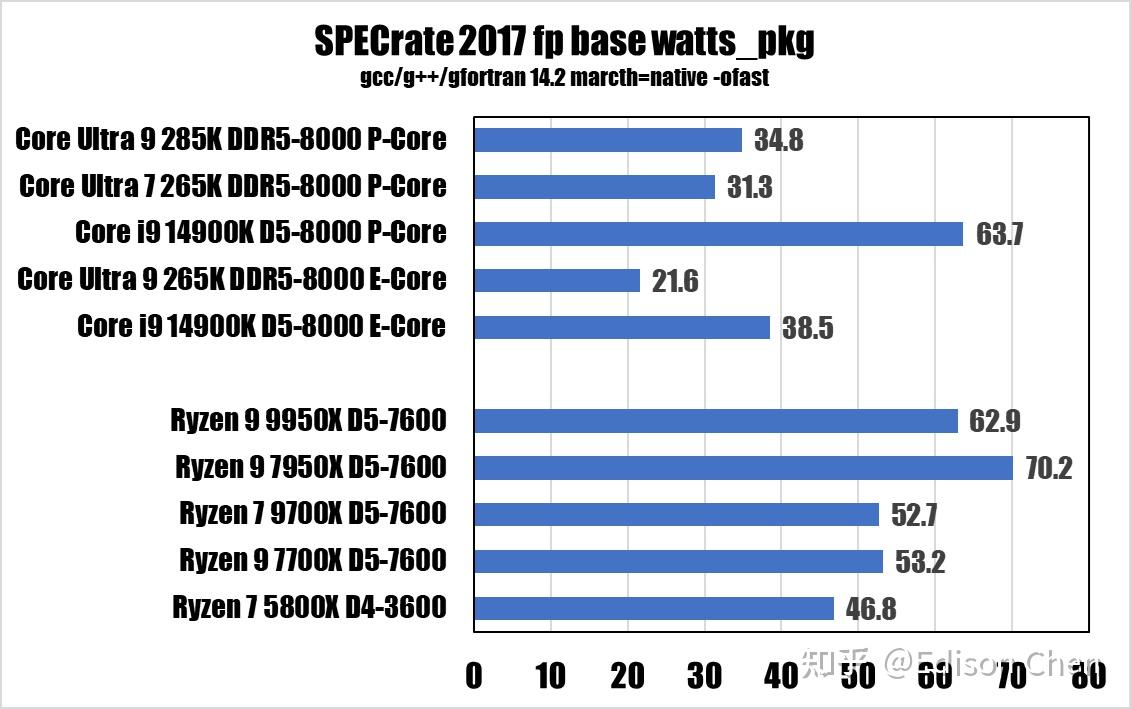
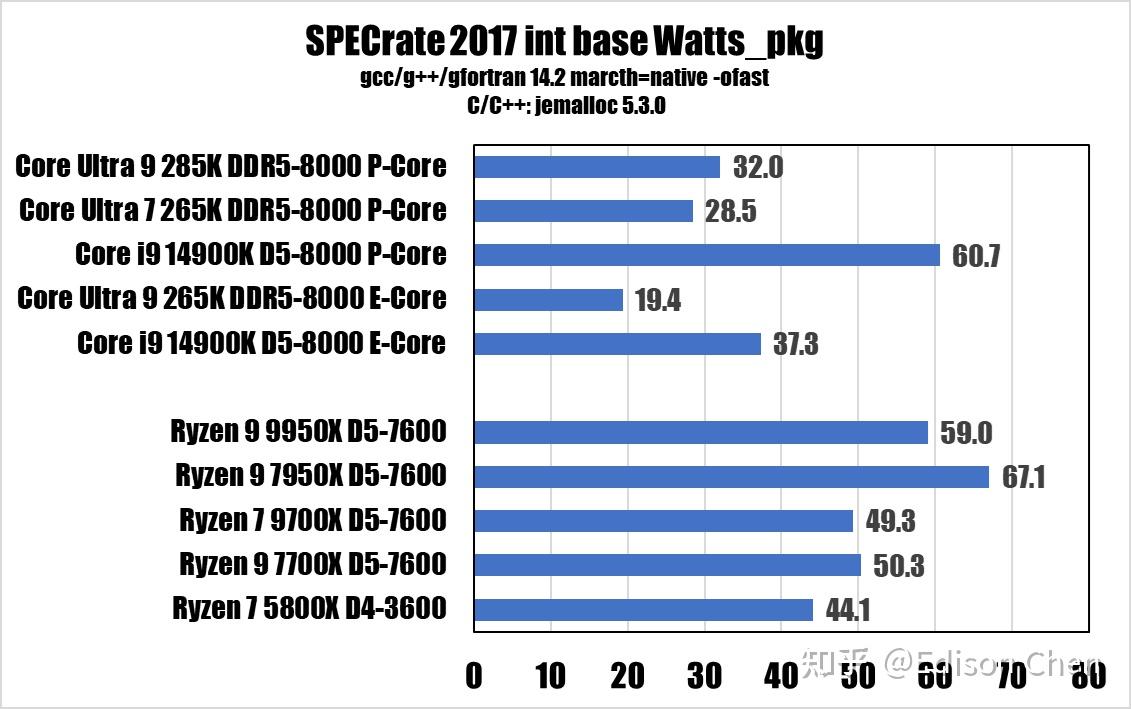
由于 fpspeed 测试遇到了一些状况(似乎是一个非常诡异的库文件相关的问题,即使 ldd 查看到所有的库文件都已经就绪),导致 621 测试会异常的低,这个问题已经困扰了两周,偶尔解决、偶尔复发,所以 speed 测试项目暂时挂起。 在 rate 测试中,Arrow Lake 的表现并不出色,优势主要是能耗比非常出色,但是毕竟rate 只是单任务的。 7z 23.01 Benchmark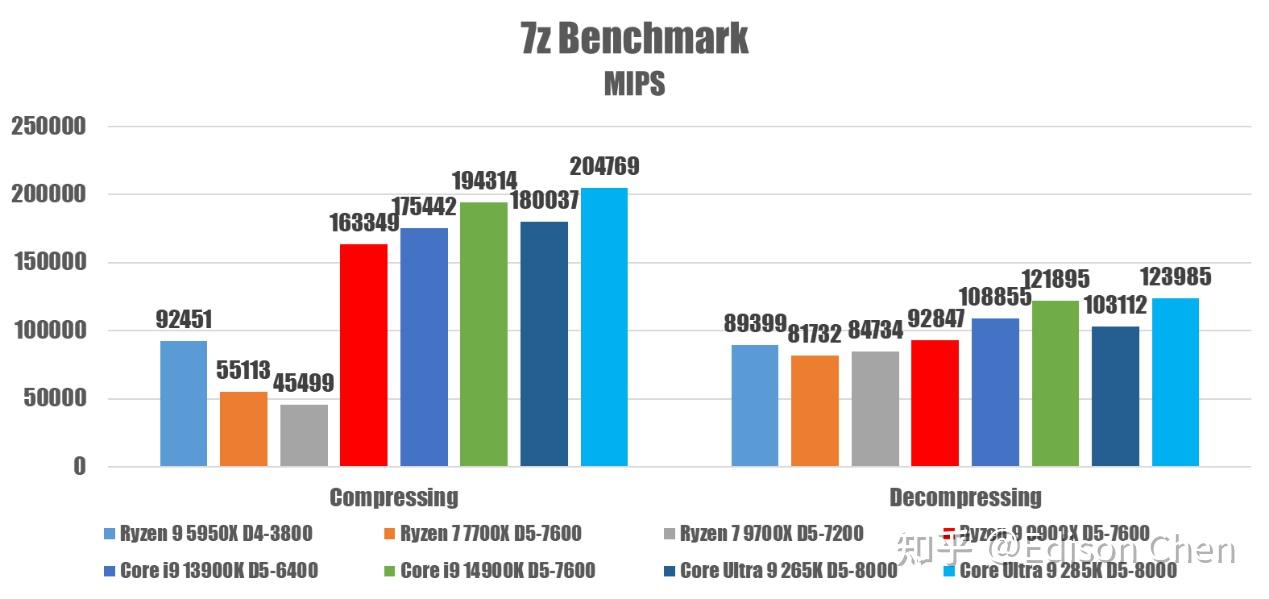
7z 是一个压缩工具,它提供了一个基准测试功能,支持多线程方式测试 CPU 的压缩、解压缩性能。 我们的测试是在关闭超线程的情况下测试的,这对于具备超线程的 CPU 来说可能有点不公平,但是我这里主要就是看这几个架构同样工况下的表现。 从测试结果来看 285K 提供了最佳的性能,但是和 14900K 相比并不占优。 AMD Zen5 可能因为带宽、流水线较深导致分支预测惩罚较大而在这个测试中表现没那么出色。 X265 视频编码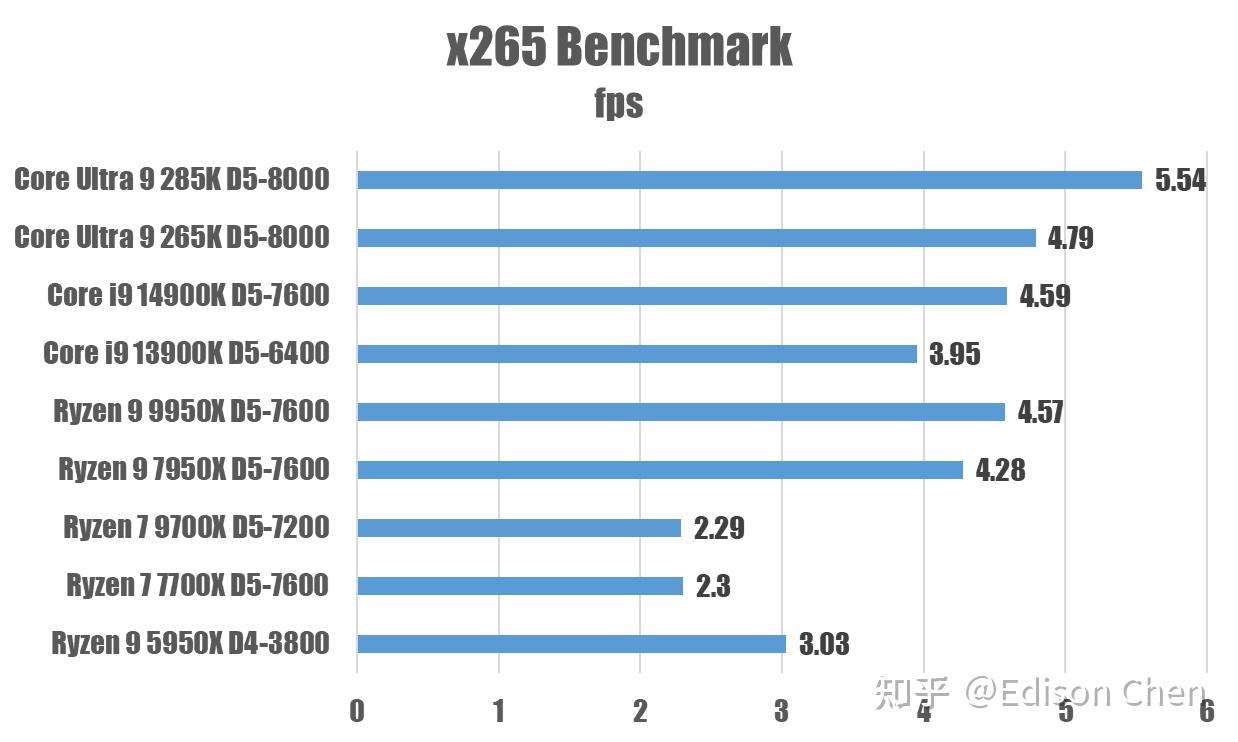
x265 是目前最常见的 h.265 开源视频编码器,它采用了大量汇编指令手工优化,是众多视频爱好者的首选编码器。 这里我使用了 duck 4k30 fps 的 y4m 文件作为输入素材,让 x265 对其进行编码,x265 命令行如下: x265 --preset slow --crf 28 --ctu 64 --profile main10 --input ducks_take_off_2160p50.y4m --output x265_encoed.mp4 在 Arrow Lake 上跑 X265 ,Skymont 的 Load 指令占比高达 77%,Lion Cove 则是 20%,这是一个非常吃访存性能的应用。 从测试看,285K 获得了第一名并不奇怪,毕竟它的内存带宽也是最高的。 评析说实话,我觉得 Arrow Lake 虽然提供了非常好的性能,但是和它的前一代相比差距并不明显,单线程的情况下甚至会出现较上一代更慢的概况,目前并不建议选择 Arrow Lake,可以的话,目前最推荐选择 14700K。 Intel 这次切换到台积电是抱着破釜沉舟的决断,然而从目前的情况看,Arrow Lake 本身虽然并没有什么问题,性能未能和上一代拉开距离这点是让人很难考虑入手的。 其他 Arrow Lake 的加分项例如 NPU 我觉得也不足以吸引大家考虑,毕竟市场上有更优秀 AI 加速方案。 Intel 麻烦了。
| 
 发表于 2024-12-16 18:01:17
发表于 2024-12-16 18:01:17
 染红的潜规则
染红的潜规则 帝爷的潜规则
帝爷的潜规则 变色卡
变色卡